
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
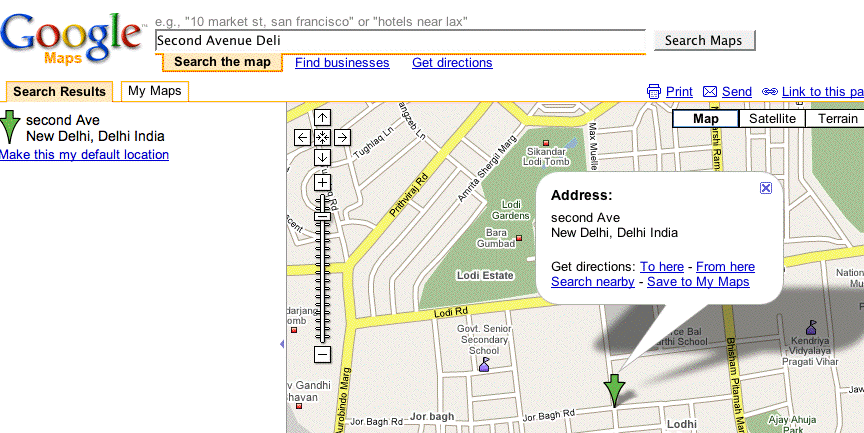
Okay let's get viral! Fred Wilson did it, I had to do it tooooo. In NYC, the Second Ave Deli is coming back Ed Levine writes a remembrance of the newest deli to open in NYC, with the same cast and food, at a new location, uptown (on 33rd St) and not on Second Ave. New York sighs in relief. So does every deli fan in the rest of the U.S. and the world. That seals it. I'm headed back to NYC before the end of the year. PS: A funny thing happened when I entered Second Avenue Deli into Google Maps. Amazon removes the database scaling wall
I was explaining the significance of this to Scoble on the phone this morning. It's worth repeating here. When I developed Frontier in the late 80s and early 90s my target platform was a modern desktop computer, a few megabytes of RAM, a half-gig of disk, a few megahertz CPU. A system capable of running Quark XPress, Hypercard or Filemaker. It would be used to develop apps that would drive desktop publishing. Later, it was used to generate static websites, then a demonstration of democracy (a multi-author ultra-simple CMS), then news sites, which became weblogs, then blogs, and editthispage.com, Manila, weblogs.com, and that's when scaling became an issue. (Later we side-stepped the scaling issue by moving most of the processing to the desktop with Radio 8.) As we approached then cracked ease of use in web authoring, scaling became an issue, then the issue. A Manila server would work fine for a few thousand sites, but after that it would bog down because the architecture couldn't escape the confines of a single machine it was designed for in the 80s. (Before you say it's obsolete, there still are a lot of apps for single machines. Perl, Python, JavaScript and Java share the same design philosophy.) Same with weblogs.com. It worked great when there were a few thousand blogs. Once we hit 50K or so, we had to come up with a new design. Eventually we were tracking a couple million, and Frontier was hopelessy outclassed by the size of the problem. If only Amazon's database had been there, both Manila and weblogs.com could have been redesigned to keep up. It would have been a huge programming task for Manila, but it would have made it economically possible.
Further, the design of Amazon's database is remarkably like the internal data structures of modern programming languages. Very much like a hash or a dictionary (what Perl and Python call these structures) or Frontier's tables, but unlike them, you can have multiple values with the same name. In this way it's like XML. I imagine all languages have had to accomodate this feature of XML (we did in Frontier), so they should all map pretty well on Amazon's structure. This was gutsy, and I think smart. They're going down a road we went down with XML-RPC and then SOAP. There may be some bumps along the way but there are no dead-ends, no deal-stoppers. All major environments can be adapted to work with this data structure, unless I'm missing something (standard disclaimers apply). Their move makes many things possible. As I said earlier, if it existed when we had to scale weblogs.com, we would certainly have used it. One could build an open identity system on it, probably in an afternoon, it would be perfect for that. A Twitter-like messaging system, again, would be easy. It's amazing that Microsoft and Google are sitting by and letting Amazon take all this ground in developer-land without even a hint of a response. It seems likely they have something in the works. Let's hope there's some compatibility. Twitter takes a break, we're awake, and wondering...
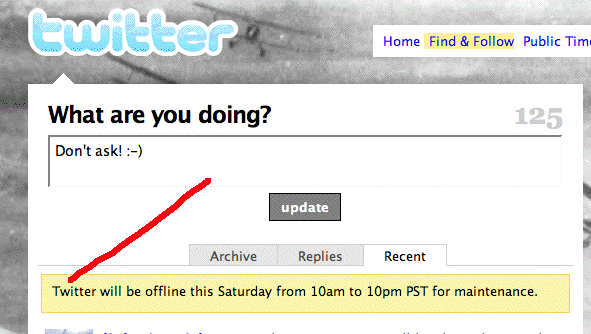
What other basic form of communication goes down for 12 hours at a time? What if the web went offline for 12 hours at a time? It's unthinkable, because the web is built on the Internet and is decentralized and redundant. A single router or server can go down for a few hours, days or forever, and the web keeps working. Same with the phone network. Imagine if all the cell phones and land lines went down for scheduled maintenence for 12 hours. Again, it's unthinkable. Even when there's a good excuse like a big snowstorm in the east, when the airline system goes down for 12 hours, a lot of people are upset, and it never happens as a scheduled thing. If Gmail started having twelve-hour planned outages, as much as I like Gmail, I'd switch. I can't be without email for any extended period of time. Okay, let's give the guys at Twitter credit -- they stopped being flip about Twitter taking naps or showers. No one likes jokes when a line of communication is down. Now I'd like them to take another step. Explain to us what these long outages are for. I can take a guess -- something about the database needs changing, and all the data in all the files must be processed to implement the change. Any updates made while such a process is running would be lost, so the server must be shut off. But this is just a guess. Another guess -- maybe they've hired a scaling expert who needs to make one final major adjustment before these outages are a thing of the past? No one would want to make such a promise, that's offering too much temptation to Dr Murphy, but that would be good news. Maybe Twitter is getting on to solid ground, finally. If so, I'd like to know. Meanwhile it's fairly amazing that there isn't a viable Twitter clone out there yet, one that does exactly what Twitter does, and runs all its applications. I'd also like to see something much more decentralized, based on static files, available to any Twitter-like system. It doesn't seem that far out of reach. With all the scaling troubles Twitter has had it's surprising that there haven't yet been any entrepreneurs willing to enter the space to compete with Twitter. Users and developers are learning first-hand why centralized systems are so fragile. I'm sure they're doing a heroic job at Twitter, the best they can with what they have, but it's not good enough when the service takes a 12-hour break while many of the humans that depend on it are awake and working. |
Dave Winer, 52, pioneered the development of weblogs, syndication (RSS), podcasting, outlining, and web content management software; former contributing editor at Wired Magazine, research fellow at Harvard Law School, entrepreneur, and investor in web media companies. A native New Yorker, he received a Master's in Computer Science from the University of Wisconsin, a Bachelor's in Mathematics from Tulane University and currently lives in Berkeley, California. "The protoblogger." - NY Times.
"The father of modern-day content distribution." - PC World.
One of BusinessWeek's 25 Most Influential People on the Web. "Helped popularize blogging, podcasting and RSS." - Time.
"The father of blogging and RSS." - BBC.
"RSS was born in 1997 out of the confluence of Dave Winer's 'Really Simple Syndication' technology, used to push out blog updates, and Netscape's 'Rich Site Summary', which allowed users to create custom Netscape home pages with regularly updated data flows." - Tim O'Reilly.
My most recent trivia on Twitter. On This Day In: 2006 2005 2004 2003 2002 2001 2000 1999 1998 1997.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
© Copyright 1997-2007 Dave Winer. Previous / Next |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 When Amazon
When Amazon  Today, when a company raises VC, it's probably because their app has achieved a certain amount of success and to get to the next level of users they need to spend serious money on infrastruture. There's a serious economic and human wall here. You need to buy hardware and find the people who know how to make a database scale. The latter is the hard problem, the people are scarce and the big companies are bidding up the price for their time. Now Amazon is willing to sell you that, to turn this scarce thing into a commodity, at what likely is a very reasonable price. (Haven't had time to analyze this yet, but the other services are.) Key point, the wall is gone, replaced with a ramp. If you coded your database in Amazon to begin with you will never see the wall. As you need more capacity you have to do nothing, other than pay your bill.
Today, when a company raises VC, it's probably because their app has achieved a certain amount of success and to get to the next level of users they need to spend serious money on infrastruture. There's a serious economic and human wall here. You need to buy hardware and find the people who know how to make a database scale. The latter is the hard problem, the people are scarce and the big companies are bidding up the price for their time. Now Amazon is willing to sell you that, to turn this scarce thing into a commodity, at what likely is a very reasonable price. (Haven't had time to analyze this yet, but the other services are.) Key point, the wall is gone, replaced with a ramp. If you coded your database in Amazon to begin with you will never see the wall. As you need more capacity you have to do nothing, other than pay your bill. 


{kind=link}
{kind=link}