
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Indiana Holmes
The kids are likely to think "You know this literature stuff ain't so bad," but this is not Sherlock Holmes it's Sherlock Potter, or Indiana Holmes. But not as entertaining. Sigh. Bad bad bad bad. And there's going to be a sequel, clearly, involving the evil and demonic mastermind, Professor Moriarity. What is seduction?
All three elements are necessary. I put this together as a response to a well-meaning commenter on my Person of the Decade piece yesterday, who observed that I was an "old" person who had done all the work being honored while in his 40s (and 50s!). I didn't ask for details, but I assume they meant that such accomplishments are usually the province of younger people. This didn't feel right to me. So I started thinking. Not to brag, but I was also very accomplished in my 20s and 30s, and in my teens I was precocious. But as an adult, which I am now, I am capable of seduction. And you couldn't launch something like RSS or podcasting, without the ability to seduce people. Because they won't move unless they get what they want, the way they want it. It never occurs to young males to seduce, because to get what they want they just have to look young and virile. Which they are very good at! If an older male wants to get some action he has to seduce. Therefore evolution taught at least some of us to do this. And that's the skill you need to make something like podcasting work. So don't be surprised if old (I hate that word) people make great contributions in the arts and technology. There are certain things, those that require seduction, that we do much better than younger folk. Example: Why it's smart to publish Realtime RSS now. Coming sooon: The Bluetooth Watch Like Checkbox News, the Social Camera and the Twitter Camera, this product is just around the corner. Someday soon we'll all have watches that do Bluetooth. Here's the pitch. Earlier this decade Microsoft started an effort they called the Smart Watch. It pretty much failed. Some people wore watches with keypads, presumably so they could do calculations or write memos. You'd have to have fingers about 1/100th the size of human fingers for that to work. I'm sure there were lots of other early attempts to digitize watches, but in the end, watches are good for telling time and not much more. The reason -- to be ergonomic a watch has to be small. But to have a decent user interface a watch has to be big. Too big. That's why the functionality that could have conceivably gone on our wrists is now in our pockets -- on smart phones, Blackberry, iPhone, Droid. In-our-pocket is the wrong place for quick text messages. They should be on our wrist! Enter Bluetooth.
I considered calling this the Twitter Watch, but enough with Twitter. They get too much free publicity. Discuss! PS: I know there are Bluetooth Watches, but they got it wrong. The display should be the whole watch face, not a sliver of tiny text beneath an analog watch face. And it's nice they can show you the caller ID, but I don't get nearly as many phone calls as text messages. A watch could display 140 characters, if you temporarily displace the time display (until you click the face to dismiss). The ones that try to be an MP3 player or cell phone are just as ridiculous and doomed to fail as the smart watches of the 90s.
Person of the Decade?!
Slate's culture podcast chose three people as Person of the Decade and they were: George W. Bush, Paris Hilton and Dave Winer. It's the weirdest thing. They said my name and no one said Who dat? I don't think it was a joke. And it was for a good thing, podcasting -- and they're right about how nice it is to have all those great podcasts to listen to. I didn't make a dime off podcasting, but in a more important way I did get rich from it. There's an incredible wealth of great stuff to listen to. It really took off, and it's something I'm really proud of. Here's the full MP3. The segment starts around minute 27. And here's the 3.5 minute excerpt where they talk about the Person of the Decade. Update: Another honor. :-) New core Frontier feature: S3 Prefs
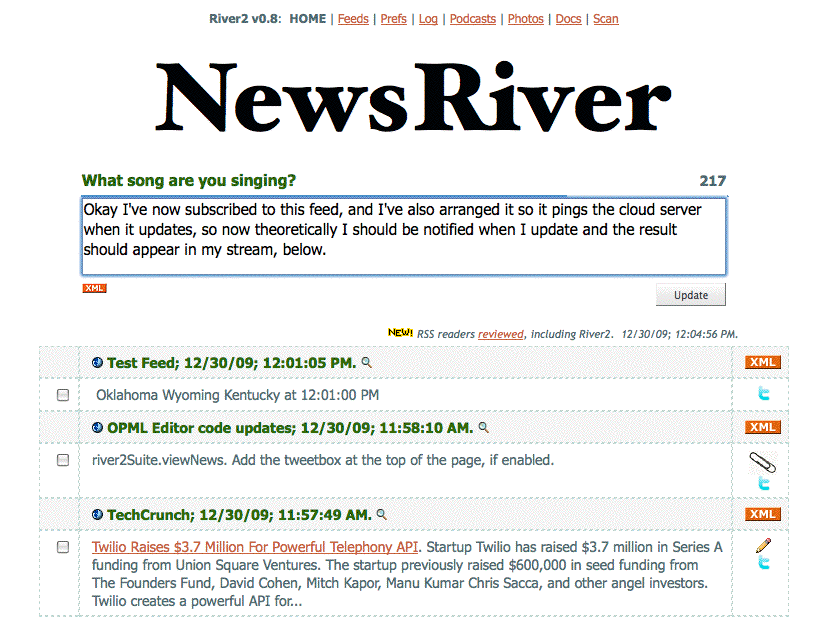
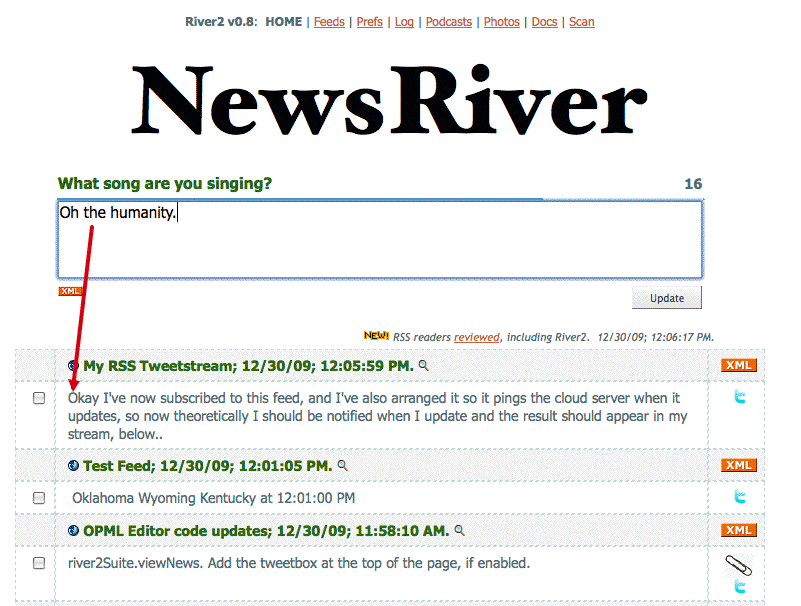
It's not much of a problem when you're running the server for them, but when the server is running on their desktop, as it is in River2, where do you put the publicly accessible content? I could operate a storage system for them, but what happens if the service doesn't take off and never becomes a business? At some point I have to punt, and that leaves users with data that goes missing. Thinking long-term I don't want to set another one of these up. The right answer is to help them get their own storage working. And Amazon has made that relatively easy, so I spent the time to make it really work. The users' feeds are stored in Amazon S3. For this I need three pieces of data. The "Access Key ID" (which is the equiv of a username), "Secret Access Key" (password) and a default bucket. That's explained on the Frontier News site. Frontier News: New preferences for Amazon S3. I created my own feed using the new tool, you can see it's on Amazon. I wouldn't subscribe to it, while it should keep updating, I'm going to merge it with my lifeliner feed. It works! My tweeting-in-the-river project has yielded a stream. Witness... In this screen shot I am composing a tweet to be published. Self-explanatory. Then a few moments later, it appears, as if by magic, in its own river. I am speechless.
Beating the drum for Realtime RSS
That's how you do it. The theory of the world beating a path to the door of the guy who invents the best mousetrap is just a story, albeit a good one. Never happens. That's why Who Invented RSS isn't a very interesting question. The hard part wasn't inventing. What was hard was getting people who are set in their ways to consider a new way of doing things. So now, once again, it's time to beat the drum, for the next layer in RSS -- Realtime RSS. The first people we need to convince are the people with the feeds. They're the chicken without which we can't make eggs. With RSS, the original feeds were Salon, Red Herring, Wired and Motley Fool. I'll never forget them. Without them we couldn't have booted it up. Then each victory added more power to the flow. It will be the same with Realtime RSS. So if you want to know why I'm so darned excited about Realtime RSS and related technologies, here's the piece to read: 12/29/09: Why it's smart to publish Realtime RSS now. Dave Winer
Anil Dash, tear down that wall
He gets that he didn't do anything to earn his placement on the list. He talks about washed-up actors who are on the list who use their follower numbers as supposed evidence that they still have pull with the people. SUL-celebs sell tweets for thousands a pop. A kid sold his SUL-enhanced feed to Microsoft. All this stuff makes you nauseous, and presumably it makes Anil ill too -- so why is he still on the list? Further, he says that Twitter will kill the list any day now, but doesn't address the fact that people who were on the list will be walking around with hundreds of thousands of unearned followers. Dan Bricklin says Anil is being a mensch, but that's ridiculous. You want to see a mensch. Let me show you a mensch. Om Malik is on the list so he has 1.2 million followers. I happened to notice this the other day while conversing with him on Twitter. I said what I felt, I was pissed at him for feeding at the trough that way. After a series of tweets I concluded that position on the SUL and links from TechMeme were both ways to keep people in line. Om, whose career could suffer for saying he agrees, said he agrees. In public, for everyone to see. That's a mensch. Anil Dash who is trying to build a career bridging the tech world and government cannot afford to appear to be in the pocket of a single tech company, yet that is exactly how it appears. And further, I know from talking with him that he understands this. Yet he remains on the list, and is keeping the account that got inflated. The only thing he can do that has any integrity, and allows his career to remain on track, is to not only ask to be removed from the list, but delete the account that got the benefit of being on the list and start over. There are no shortcuts possible here, imho. Marrying RSS and Twitter
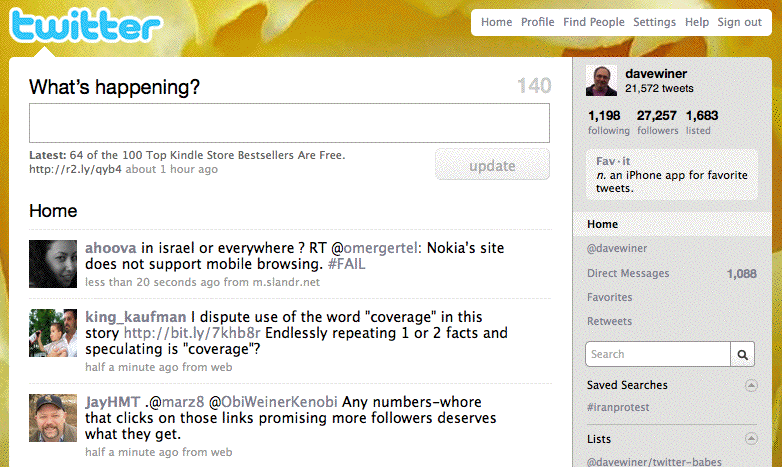
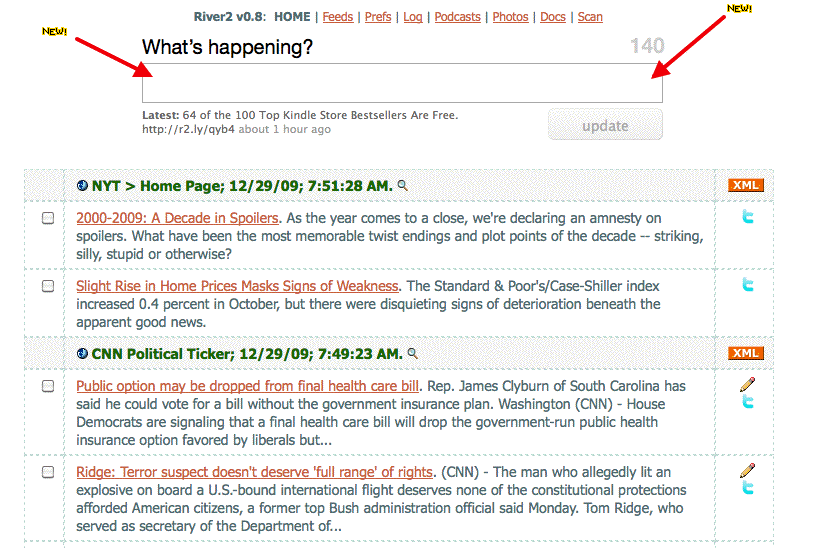
Maybe a kind of breakthrough. So here's the peanut butter -- a screen shot of the River2 aggregator. You can see at the top there's a big logo doing nothing, and below it is a list of new articles. This is what I call the River of News, it's what Twitter does so nicely. Or more precisely it's one-half of what Twitter does so nicely. And here's the chocolate -- a screen shot of Twitter. Where I have my logo it has a small text box for entering a 140-character message. And here's the new idea. What if you took the text box from Twitter and put it at the top of the River? Where would the text go? Ahhh that's easy -- a Realtime RSS feed. And from there it could flow into other RSS rivers and of course into Twitter or Facebook or anything else that likes streams of 140-character messages. I'm going to do this in the next couple of days and see how it feels.
Frontier News blog re-start I've started a new blog to document the root-level work I'm doing in the OPML Editor. http://frontiernews.org/2009/12/28/welcome-to-the-frontier-news-blog/ In a way this is not a new blog at all. Frontier News is a very old name in our community. Before there was Scripting News, I had a blog that documented work we were doing in Frontier. So in a sense this is the continuation of a thread that goes back to 1996 and before that, to the CompuServe forum and support we were doing on AppleLink starting in 1990. Big wheel keep on turning!
Coming soon: A Twitter camera
Imagine a Twitter-branded camera. Here's how it would work. It would have the inverse of Amazon's Whispernet. Where Amazon wants to push content to the remote device, the purpose of the Twitter camera would be to push the content, pictures -- to Twitter. The user interface would be simple. Take a picture. It shows up in the little screen built into the camera. There would be a blue button with the Twitter bird on it. Click the button and the picture being displayed is uploaded and a pointer is tweeted on your behalf. One-click publication from anywhere a cell phone works. Ultimately cameras will be able to communicate. Until today I didn't realize that they would be hard-wired into social networks. I'm sure they will. Of course there will be a Facebook camera. And if Yahoo had been paying attention there would have been a Flickr camera, two or three years ago. A UStream or Qik HD camera would be good too. The key point is that the device and the online service will become inseparable and least for casual point-and-shoot people, like myself. CloudPipe changes for today More work on CloudPipe. Yesterday's notes here. Getting some feedback finally, though some of it has been bitter and condescending. Please everybody. Be respectful of everyone, including yourself. And remember: Tis the season to be jolly! Peace on earth, goodwill to men. Ignore the grouchyness and try to find the substance. Even better if people self-edit and leave out the michegas. Now on to the substance... 1. There is support for not normalizing the items, and that is still the plan. It's true, there's a lot of code out there that understands all the varieties of RSS and Atom. I've been saying that all along! The reason to do fatPing is to start a bootstrap that makes everything more efficient. In this, the leadership will come from the content systems and the aggregators. 2. I've made a change to the body of the fatPing element. Instead of including the XML elements inline, I encode the text and pass it as CDATA. This means that it will make it through XML parsers that care about namespaces being declared. An example, I was passing through an item from the TechCrunch feed (they support rssCloud, btw) and they have elements from the DC namespace. My packet doesn't declare this namespace, so the Firefox XML parser declares it invalid (they're right about that). I have to encode the text because they might include CDATA elements, and that would break the XML. Let's see if this works! 3. The point has been raised that there is no "standard" way to include a <cloud> element in Atom feeds. As I said in the comments, I will not be the person to dictate that, or suggest a way to do it, even mildly. I've learned that Atom is a 300-degree stove. When I touch it I get burned. However, I am the author of an aggregator that consumes Atom feeds. If you are the author of software that creates Atom feeds, you could (just saying hypothtetically) create a namespace that contains the <cloud> element in it, as spec'd by RSS 2.0, and include it in your feed. If you told me about it, I could implement support for it in River2. That way we keep it all among implementors. There can be no doubt that you have the right to do that, and I have the right to support it. If anyone wants to get grouchy and irritable, let em! 4. To notify the CloudPipe server what feeds you want realtime notification on, send a POST to the same endpoint you call for the long poll (instead of a GET). The body of the POST is the OPML text for the feeds you want to follow. The server returns immediately while it processes the request. 5. The biggest development of the day is the draft spec is now ready for review. Please read the "Document Status" section carefully and believe what it says.
Update on CloudPipe work
I'm getting pretty close to the point where I'll write docs and put it up for review. But I wanted to post a heads-up now that I've made a change in how it works, a difference between the actual protocol and the December 9 narrative. It says: "When the server detects a change in a feed the client is subscribed to, either through polling or notification, it sends a packet to the client indicating the feed has changed. The client then reads the feed, and processes it the same way it would if it had detected the change through polling." The client may read the feed but I implemented and will specify a "fat ping." Along with the URL of the feed, we send the content of the item. If there are two items that changed, then two complete fat ping packets are sent. (This should answer in advance the question of how many items may be contained in a ping -- one and only one.) I went this way for two reasons: 1. Competitive -- It's often mentioned as the reason people prefer PubSubHubBub over rssCloud. By providing for a fat ping, we erase that advantage. Now the two methods are at least at parity, with an edge to rssCloud because, once CloudPipe is done, it will work for clients that are behind firewalls and NAT, and PSHB does not. 2. Efficiency -- I learned when I met with the Tumblr guys in NY earlier this month that their feeds get pounded. The number one most referenced pages on their sites are the feeds. When I was running UserLand, it never was an issue, but we had a very small fraction of the traffic that Tumblr, WordPress, Blogger, Typepad etc have. Now that I know it is an issue, I want to address it. By sending the content along with the ping, in the realtime layer that's building now there will be fewer feed reads. Now there's the question of whether to normalize the contents of an item. I can do it, but it might be a politically sensitive issue. Right now I have bigger fish to fry, so I won't normalize items, what you get in the fat ping is exactly what the feed broadcast. You'll have to deal with all the variability that can appear in the various flavors of RSS and Atom. I could make it so you didn't have to, but... We'll get to that later. I expect to have a server for people to test against and docs for the protocol before January 1. Knock wood, praise Murphy, etc etc. Update: Here's a 5-minute podcast that explains what these fat pings are all about. A new Facebook API Christmas is over but we're still hoping for lots of goodies in a new API from Facebook. I explained over on the Realtime RSS blog yesterday. Realtime RSS: Dear Santa: Please, a new Facebook API. This is part tea-leave-reading and part pure conjecture, with a huge does of wishful thinking.
Enjoy!
How I develop formats and protocols
1. First, I have to understand the problem. That might take a month or more of walking around Berkeley or New York listening to music and podcasts. When I finally feel I grok it enough to begin coding, I need to have at least two apps. One that produces the format and one that consumes it. So I start by writing very simple versions of those apps and usually run them on the same machine to make debugging easier. 2. I connect them with a protocol that I know won't be the one I will use, but models it in some fashion. In the app I'm working on now, I had the server wait a random amount of time before returning the name of one of the 50 states chosen at random. On the client side, I have it open a connection to the server and wait until it gets an answer, which it just records in the database. 3. Once I have the two apps conversing this way, I start to make the conversation meaningful. I take my time, really slow down and think, try out lots of approaches. I also do a lot of prior art searches to see if I can pick up ideas from people who came before. In this case, I looked at FriendFeed's realtime API, but I came up with something that's a bit simpler. It could be that the previous protocol can do more than mine, but I just wanted to flow updates across firewalls and NATs. (Even so, my protocol has a lot of room for growth.) 4. Once I've settled on the format, and this could take a few days, I then split the apps between a real server and client and start to test it doing the work it was intended to do. Since I haven't done that yet, I can't tell you how it will go. I might loop back to step 3 and change the format based on what I've learned. I will certainly add logging features and metadata to the payload to enable debugging and performance monitoring. 5. Once I'm satisfied that it works, I write an informal document for discussion and review. I don't sneak a look to friends or people I like. If I did, that would violate the very important principle of keeping the playing field level. Instead I'll post the document publicly and post pointers in various places, on the rssCloud mail list, on Twitter, probably on the Frontier-Kernel list since I'm trying to reactivate that community after a long period of staying out of it.
I have participated in the working group style of format definition, what I called the "deliberative approach" in yesterday's piece. But I don't like the results that come from that. I believe in designing these bits of tech as much as Jonathan Ive would design a new iPod or BMW would design a driving machine. To me this is an art, and in art there are always choices, and someone has to make them. The deliberative process is all about not making choices, putting all the possible ways of doing something in the spec. This gives an ego boost to the people on the working group, and a lot of grief to the engineers who have to deploy. In the end you have multiple profiles and lots of missed opportunities for interop. Having one person act as designer may hurt some egos, but the format works better in the real world.
Open is in the eye of the beholder When I say the Twitter API may be an open standard, I mean something different than when Jonathan Rosenberg says Google likes open standards. I mean it's open in that anyone can implement it now. A smart developer can implement the Twitter API in a matter of weeks. Rosenberg means that the process of defining the standard is open. He would start a process to define a standard that in two or three years a team of 20 programmers could implement in another two or three years. Those are the kind of results that his version of "open" delivers. In an ideal world I prefer defacto standards that are ratified by unanimous consent by standards bodies. The deliberative process yields bad results for several reasons: 1. The defacto standard doesn't just shrivel up and die, despite the best efforts of the latecomers to force it to. Twitter isn't going to shut off its API and kill its developer base because a working group formed. 2. You end up with two ways of doing something, and two ways are worse than one, no matter how much better the new way is. As Anil Dash says, the Twitter API is now, for all practical purposes, finished. 3. The new way is never better because the deliberative process yields a design by committee. SOAP failed to be a source of interop for just this reason. The working group had hundreds of members and pleasing even some of them meant creating a spec that was so vague and rambling as to be pointless as a standard. It provided almost no interop. (BTW, I am an author of the first version of SOAP, so I got to watch the deconstruction of a standard by a working group from the inside.) Dare Obasanjo of Microsoft asks us to look at the process by which RSS begat Atom as a cautionary tale. He says the designers of Atom had "no choice" but to be totally incompatible with RSS, but that's not true. They could have started with RSS, and only deviated where absolutely necessary. I urged them to do this.
Microsoft welcomed the W3C to the standards process when Netscape threatened the dominance of the Windows desktop in the mid-90s. The W3C gave them a greater-than-equal voice to Netscape, even though they had nowhere near Netscape's market presence in the dawning market of the web. In 2009, Google is just beginning to be a presence in realtime. It's fairly thrilling to see realtime search results show up in Google searches. They should keep going but hold back some of their power to let the little companies have a chance to do what they do better -- drive innovation. If Google does what Microsoft did, and unleashes all their destructive power, they will destroy the market. And we will be left with a scorched battlefield instead of the growth that's promised by the blossoming prototype of the news system of the future that I believe Twitter is. I've said all along, as I said with Netscape in 1994 -- Twitter desperately needs competition to toughen them up and make them more responsive to market opportunities. To give them a sense of urgency they lack. But what they and we don't need is Google and other big companies to stall the market in the name of being open. Their process is open only if you're a BigCo, and shuts out exactly the people we want in there. The gutsy bright-eyed young entrepreneurial minds at rising stars like WordPress and Tumblr. They are ready for a standard now, not someday in the future, after a huge working group is finished with it. Not two years after that when everyone has forgotten the Open Microblogging Intitiative or whatever it ends up being called. They're ready now, and so is the market. So Google, Microsoft, Facebook, et al should step back and consider how they can help now, and not throw obstacles in the path of a surging market. My argument to Microsoft 15 years ago was that they would get the lion's share of any growth that is achieved by the upstarts, so it worked against their interests to slow them down. That still is true today, but there are new players who own a large share of the future, no matter what. Don't screw it up.
Store Twitter URLs in earth's oceans?
Brilliant. Wish I had thought of it. A great idea that illustrates how silly this situation is -- where links are treated as an afterthought. Links, which form the foundation of the web, are shortened, made more fragile, meaning removed, the web made slower. If Tim Berners-Lee weren't alive he'd be rolling over in his grave. But what Mike says is actually slightly practical. Come up with a way to map domains to tiny plots of ocean space (presumably people can't occupy space in the ocean and 2/3 of the planet is covered with water). How many domains would that be? A lot. Can you estimate the actual number? Any help would be appreciated. Then the numbers to the right of the decimal points would map to URLs on the site, the same way short URLs map to them. Each site would manage its own space. Voila! No need to include URLs in the 140 characters. Goodbye shorteners. Now all you have to do is get the client companies (and that includes twitter.com, the largest client) to go along. If it weren't so sad it would be funny. Maybe that's why it's so funny. Come on Twitter -- Make room for the URL as metadata. It's way past too late. If you wrote the words you own the copyright At Poynter Paul Bradshaw asks a question with an obvious answer. Paul Bradshaw: In the E-mail Era, Who Owns the Interview? Obviously the person who wrote the words owns the copyright. Fair use allows the reporter to quote them. I can't imagine a lawyer advising or a court deciding otherwise. And of course this highlights the fact that a lot of people help reporters and news organizations, without any hope or expectation of compensation. It's funny that none of these people are mentioned in the sad pieces that wonder if the news industry has a future. And no one seems to see an even more interesting question -- in the age of blogs, do we still need reporters? (I think we do, but not as much as we used to.) Why today's Twitter is like Napster in Y2K
If you believe, as I do, that Twitter is at least a dress rehearsal for the news system of the future, it's pretty clear we're at a Napster-like place now. Everyone has a name prefixed by an at-sign that takes you to their profile page. Twitter is, right now, the default identity system for the realtime message network. But that is changing very quickly. Recently Facebook changed the meaning of at-sign to take you to your Facebook profile page. And on WordPress and Tumblr the at-sign will presumably take you to your home blog or profile page on either system. It's hard to imagine them defining it as your profile on Twitter. Technically it would be nearly impossible for them to do it. And politically, it's not very appealing. A few years from now we may look back at the Twitter of 2009 as we now look back at the Napster of 2000 -- a time when there was a great opportunity to build, that was missed. In this case, it's the owners of Twitter who are missing the opportunity. They could now be defining the loosely-coupled version of Twitter, and let your home page on Twitter act as the glue that joins all the networks you belong to that link through your Twitter ID. The address of my Tumblr profile page could be: http://twitter.com/davewiner/tumblr And my WordPress profile page would have this address: http://twitter.com/davewiner/wordpress And the implementation of the Twitter API on twitter.com would have new features that make it easy for me to find other API implementors of networks that join together through my presence on Twitter. There probably isn't enough time to architect this, but maybe there is. It's certainly worth thinking about.
Tumblr and the Twitter API, day 2
Fred Wilson, who is a Twitter board member and a major investor in Tumblr, wrote a post on his blog asking for a discussion among his readers, who tend to view the tech world from an investor's perspective. It's great that APIs finally have become an issue for financial people. They're also important for media people because they open doors in the news business as well. In this week's Rebooting The News, Jay asked me to explain what it means for WordPress to implement the Twitter API. The podcast was recorded before we knew that Tumblr was working on matching WordPress. If you're confused by all this michegas, listening to the podcast might help. On October 17 I wrote The Internet Abhors a Funnel. In a sense all these new implementations of the Twitter API tend to lessen the importance of teh Funnel. And in addition to strengthening the position of WordPress and Tumblr, it also strengthens Google and Microsoft, because their search engines can become more complete than Twitter's, by making deals with the new players for access to their firehoses. Stowe Boyd asks this question from another point of view. How do you follow someone on Tumblr from Twitter and vice versa? I have two answers for that: 1. That further strengthens the position of centralizers, Google and Microsoft. 2. That's what Realtime RSS is for, the concept behind rssCloud and PubSubHubBub. 3. Twitter can and probably still should position itself as the Network Solutions of this space, as I outlined in my 2007 piece that broke Twitter down into its components.
Health reform politics in 106 chars Just like there are no atheists in foxholes there are no Republicans who are uninsured and critically ill. How open standards are created
Well, less than a week later, Tumblr now has implemented the Twitter API, and as a result you can use any Twitter-compatible tool to post to and read from Tumblr. Let's pause here to let that sink in. Wow. Unbelievable. Fantastic. Awesome. Conventional wisdom says that open standards are created by endless deliberations among experts and big tech companies, and those do sometimes gain traction. But this is how it usually happens: Someone goes first. No one thinks of it as an open standard. Then someone clones it. All of a sudden people get ideas. Inspired, someone goes third. At this point it's inevitable that there will be a fourth and fifth and so on. It's also inevitable that Twitter tools vendors will start testing their products with WordPress and Tumblr, and hopefully report bugs and have them fixed. And the brilliant minds of the developers and users of WordPress and Tumblr will have their say in the evolution of this new art. All of a sudden things are exciting again!! PS: If Facebook were to implement the Twitter API that would be it. We'd have another FTP or HTTP or RSS.
A new Internet Law, named after Bill Gates
Sometimes I even win when they try to make me lose. But you gotta wonder why a big company like Google wants me to lose. Wouldn't it be easier if they outsourced some of the innovation and got the seal of approval you get when someone who's truly independent says there's nothing up your sleeve? Otherwise I'm almost sure there is a hidden agenda. Esp when patents surface on stuff they didn't invent. Had the same problem with Microsoft, multiple times. Funny how no one makes the pilgrimage to Redmond these days. It seems to me the rest of the world has a say in teh future Mr Google. I said this to Microsoft and now I say it to you. Relax. Kick back. You're going to make 40-plus percent of all the profit that comes from any growth we, outside of Google, are able to create. Maybe even more. You won't get any more growth if you insist on controlling every bit that goes over the wire, in fact you'll get less, because the more you impede overall growth, the less you will grow. Of course I can't prove this, but it was definitely the right call in the layer before yours. Somehow I think it's a fundamental rule of the growth of the net. The current leader will always try to control growth, and thus slit its own throat. Call that Gates' Law, because he both discovered it (as it applied to IBM) and fell victim to it (in his struggle to control the web). BTW, to Aaron Swartz, who says Google is much less of a sociopath than Microsoft. I don't actually think so. Microsoft wasn't as bad as you seem to think. They didn't interfere with 99 percent of all Windows apps. They certainly never tried to control the platform anywhere as completely as Apple tries to control iPhone apps today. I think it's very nice of Google not to screw around with search results. I also think if they did, they'd instantly fall apart. Another BTW, in showing us the future Google Toolbar and Feedburner, yesterday, Google presented a classic Embrace & Extend. You can tweet your links to Twitter, and a number of other places. At some point they will add Google's Twitter clone to the list (unless they acquire Twitter of course). No matter what it will be the default. You can feel its presence. Not a bad thing. A way of reminding Twitter that they are still very much one of us. Might end up being a very good thing. Build to flip? Lots of interesting developments yesterday, and I'm glad to have a front row seat. Actually in some cases I have a seat in the dressing room, so I have to be pretty careful about what I say. First, New York has become much more interesting in the tech world. I spent just two days hopping from rock to rock, and didn't land on most of them, but wow, there's something going on there. In New York as on the west coast, some companies are built to flip, meaning they don't intend to be standalone companies. They were just building features or market share, intending to be bought by a big company, probably Google. Pretty sure that bit.ly, a company I played a role in founding, was running a Build To Flip plan. I think we found out yesterday that it didn't work. I think in general, even if your plan is to flip, you should run a company as if no one will buy it. That your liquidity will come in the form of profit from sales of services and products to users. It's good discipline. Keeps the team focused on who and what's important. Had bit.ly been running such a program, they would be a lot further along with Bit.ly Pro, a service they announced yesterday, probably in response to Google's announcement of their URL-shortener. (If it wasn't a response it was an incredible coincidence in timing.)
Back to New York. The big question I have for the brilliant young tech startups of New York is this -- are you trying to become an outpost of Silicon Valley or are you wanting to build a new layer on tech, independent of the west coast? BTW, it's not all a rotten mess on the west coast. I have become a huge admirer of Matt Mullenweg and Automattic in the last year (not that I wasn't already smitten before). They did two beautifully disrupting things in 2009 all while growing their freemium cash-generating business -- they implemented rssCloud and the Twitter API. And the year still ain't over.
Now that Google has a URL shortener
For example, Google Maps has the ability to generate a link to the map you're viewing, suitable for sharing with others. But the URL is a monster mess. Why not make it short? I first suggested this in November 2007. Also: It's about time Twitter put the fork in URL shorteners for good and transported links as metadata of the tweet, as they do for geo data, the post time, etc. Why are they sacrificing the stability of the web to keep bit.ly alive. I still don't get it.
In NY this week I've spent the week in NY on business and family stuff, having a nice time, but I didn't bring warm-enough clothes. We're definitely in transition here, I now write for a lot of places, and Scripting News has become very quiet. Pointers to all my writing can be found on protoblogger.com. Uncle Arno's books found a home In October I wrote a post looking for a home for books written by my great-uncle Arno Schmidt. The books were left to us by his sister, my grandomother, who was keeping them for him in the US. Turns out most American universities with a German Studies department already have complete sets of his writing. However, Timm Menke of Portland State University posted an enthusiastic comment under my post. We exchanged emails, talked on the phone and we quickly decided that they would provide the best home for his work in the US. Yesterday the books arrived in Portland. If anyone is looking for a good collection of Arno Schmidt's work in the US, selected by the author, you should look to Portland State University.
RSS for BitTorrent, and other developments TorrentFreak has a piece today talking about my efforts to sort out the differences in the RSS used by various BitTorrent websites. I also posted some ideas for a Torrent namespace that can be used in RSS, or any other XML-based format that accepts extensions, such as Atom and OPML 2.0. On the Droidie site I look at what it will take to make it the perfect podcatcher. And a think piece on Protoblogger on the tension between doing something big and getting rich. This will lead to a followup piece that talks about creating incentives for people who don't want to go the corporate route. There really isn't that much money at stake but the really large ideas suffer if they get caught up inside corporations. Twitter has been down now for about 1/2 hour. 3:30PM Pacific. Oy -- we're so dependent on it. Where would you go now to find out what's up? status.twitter.com has nothing about an outage. (Postscript: It was down for just about 1/2 hour. TechCrunch has a story about it.)
Recent stories As usual, check out protoblogger.com for a list of all the stories I write on the various sites I write for. Here's a subset, the ones I don't think you should miss. 1. I'm sorry but we need government. 2. Ideas for a BitTorrent namespace. 3. What does the J-school of the Future look like? 4. Consumer Reports rates cell phone service in the US. 5. We need: A programmable Twitter client.
Have you tried Google's DNS? This morning Google announced that they're now running a free DNS for everyone to use. The IP addresses: 8.8.8.8 and 8.8.4.4. Interesting and unexpected. Why? Obviously they get a lot of data -- all the sites we're visiting. Have you tried it? If not, why not? If so, how is it? They say it's faster -- is it? They say they won't screw with it. Do you believe them? Update: I'm using it here on my LAN. Just changed the configuration of my router, so all my machines will start using their DNS.
Why is technology important?
I asked JP if any of the technologists he employs could explain why technology is important. It was kind of a challenge, because I find that so many people who call themselves technologists don't have an answer to that question. His talk was about this subject, so I thought it was fair to bring it up. Had I been interviewing him I would have. Anyway, the answer: Technology is important because it empowers people. That's where you start. Not in novelty or neatness, not in the fact that it changes things, because it might change things by disempowering. Change is not in itself a valid reason for anything. The only reason to have technology is that it gives people power to change things for the better. Note that the technology is not the subject of that sentence, people are. I don't think you can even begin to be a technologist if you don't have a passionate view about technology's importance. It has to be the reason you're doing it. Not because you have an aptitude for it, or want to make a lot of money, or want to change the world, or prove yourself or show your father (uncle, mother, sister, brother, best friend) that you have the stuff to make it. None of those things make a technologist. If you're not thinking about people, all the time, in everything you do, then you're not a technologist. Usually I put an "imho" at the end of statements like that, but this one is so important, I'm leaving it off.
We need: An open source Twitter shell
In my explorations of a hypothetical decentralized Twitter, at first I thought the clients would be where decentralization would happen. But, lately I've come to realize that it probably won't happen there because as the market has evolved they've become too dependent on Twitter Corp, and are unlikely to do anything that might threaten a friendly relationship with the company. I saw this first-hand in the Mac software market in the early 90s. Even when it would have been in the interests of developers to work with each other, each of them tried to do special deals with Apple. Of course no one really got those deals, so we all went down. But it's human nature to think you're special and if you play nice with the platform vendor, they'll play nice with you. And the platform vendor may totally mean to be nice, but they can't help acting in their own self-interest and that almost always is at the expense of the developers. So if the commercial developers can't or won't break free of the platform vendor, let's create an open source client that can be repurposed in as many different ways as we, as individuals want. Some of us may want to do deals with Twitter Corp, and that's fine -- but others may wish to embark on paths that are independent of Twitter. They wouldn't try to guess what would make the platform vendor happy, and instead follow the grain of the Internet, or go where the users want to go, or some users, or to scratch their own itch. Some may want to be part of the Cathedral and others part of the Bazaar. :-) I'm not even 100 percent sure what I'm asking for, but I'll know it when I see it. Probably a JavaScript framework that comes with a Twitter timeline object. So displaying a timeline is automatic as are the user interactions. So any kind of client, one written in any language -- Python, Perl, Java, JavaScript, PHP, C, etc -- could store data in it. It wouldn't know anything about the Twitter API. It would be up to the applications to put data in the structure. It would do more or less exactly what the twitter.com website does. Same prefs, same commands, same user experience. Think Apache for the Twitter user interface. It would, of course, be programmable through a user scripting language. Having this one component would let a thousand flowers bloom in exactly the place where we need them to bloom. The key thing is to find out what would happen if we could take a path that was not designed to please the platform vendor. Note I carefully did not say "to piss off the platform vendor." I really do mean to chart courses that are independent of the vendor. What would be even cooler is if one of the client vendors decided to release their code under the GPL. Or, even better would be if Twitter Corp did it. That would be hugely disruptive and would likely lead to some very serious innovation. :-) Teen tweeter cashes-in on SUL placement BBC: "A Twitter feed set up by a Dutch teenager as a hobby has been taken over by Microsoft news channel MSNBC.com." The report emphasizes the rate that the feed is growing, by 3000 to 4000 followers per day. What it doesn't say is that the feed is on Twitter's Suggested Users List, and that growth is normal for feeds on the list, even ones that aren't run by prodigious teens. Editorial comment: Might as well say that a Dutch teenager amazes his parents by traveling from Europe to America in a matter of hours. Without saying that he booked a flight on KLM. :-) We live in a time of pseudo news. Another observation. It would be interesting to know how much Microsoft paid for his feed. That would, right there, establish the monetary value of SUL placement. |
"The protoblogger." - NY Times.
"The father of modern-day content distribution." - PC World.
One of BusinessWeek's 25 Most Influential People on the Web. "Helped popularize blogging, podcasting and RSS." - Time.
"The father of blogging and RSS." - BBC.
"RSS was born in 1997 out of the confluence of Dave Winer's 'Really Simple Syndication' technology, used to push out blog updates, and Netscape's 'Rich Site Summary', which allowed users to create custom Netscape home pages with regularly updated data flows." - Tim O'Reilly.
My most recent trivia on Twitter.
On This Day In: 2008 2007 2006 2005 2004 2003 2002 2001 2000 1999 1998 1997. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
© Copyright 1997-2009 Dave Winer. Previous / Next |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Went to see
Went to see  To seduce someone is to: 1. Find out what they want. 2. Give it to them. 3. The way they want it.
To seduce someone is to: 1. Find out what they want. 2. Give it to them. 3. The way they want it. I don't know the economics but I imagine a digital watch could be made to look beautiful and also to have a mode where it couples with our phone and acts as a receiver for text messages. That way every time someone DMs you on Twitter it could show up on your wrist, with a little vibration only you feel.
I don't know the economics but I imagine a digital watch could be made to look beautiful and also to have a mode where it couples with our phone and acts as a receiver for text messages. That way every time someone DMs you on Twitter it could show up on your wrist, with a little vibration only you feel.  You aren't going to believe this.
You aren't going to believe this. I hit the same wall I always hit when looking for a place to store the users' content.
I hit the same wall I always hit when looking for a place to store the users' content.  People always get tripped up on what I had to do with RSS. One thing I did a lot of, for sure, is beat the drum. Every little development, every new source that came online, I'd hail it here on Scripting News as the greatest thing that ever happened.
People always get tripped up on what I had to do with RSS. One thing I did a lot of, for sure, is beat the drum. Every little development, every new source that came online, I'd hail it here on Scripting News as the greatest thing that ever happened. Anill Dash ran a
Anill Dash ran a 
 I've been trying to find an easy way for my mom to manage her own digital camera, and have settled on getting her a netbook computer she can travel with. I'll set it up so it's easy for her to take the SD card from the camera and plug it into the netbook and upload her pictures to Flickr. It'll be pretty easy, but then I was just driving home from dinner and realized that someday, maybe very soon, it will be even easier.
I've been trying to find an easy way for my mom to manage her own digital camera, and have settled on getting her a netbook computer she can travel with. I'll set it up so it's easy for her to take the SD card from the camera and plug it into the netbook and upload her pictures to Flickr. It'll be pretty easy, but then I was just driving home from dinner and realized that someday, maybe very soon, it will be even easier. As I noted in a
As I noted in a 
 I don't think I've ever written a blog post that explains how I develop formats and protocols, probably because I was afraid of getting flamed. Nowadays I'm not so afraid, so here's how I do it.
I don't think I've ever written a blog post that explains how I develop formats and protocols, probably because I was afraid of getting flamed. Nowadays I'm not so afraid, so here's how I do it.
 All this talk about open standards processes is surfacing now because WordPress and Tumblr implemented the Twitter API, thereby putting the "defacto" ball in play. The BigCo's don't like it because, like WordPress and Tumblr, they're late to the game and don't want to play on the same field as the little companies. They want to force Twitter into a standards process, I assume. It's something Twitter might consider, but they should be cautious.
All this talk about open standards processes is surfacing now because WordPress and Tumblr implemented the Twitter API, thereby putting the "defacto" ball in play. The BigCo's don't like it because, like WordPress and Tumblr, they're late to the game and don't want to play on the same field as the little companies. They want to force Twitter into a standards process, I assume. It's something Twitter might consider, but they should be cautious. 
 One of the arguments for the music industry not suing Napster out of existence in 2000 was that they had all the music on the Internet under one roof.
One of the arguments for the music industry not suing Napster out of existence in 2000 was that they had all the music on the Internet under one roof. 
 Marco at Tumblr says that he was inspired by the "seriously clever" use of the Twitter API by WordPress. Of course I was too. When they came out with it I
Marco at Tumblr says that he was inspired by the "seriously clever" use of the Twitter API by WordPress. Of course I was too. When they came out with it I  I get more than my share of flack from Google which is really strange because I am a person and they are a multi-billion dollar empire that employs thousands of people.
I get more than my share of flack from Google which is really strange because I am a person and they are a multi-billion dollar empire that employs thousands of people. 
 They should start
They should start  I just wrote a piece about the
I just wrote a piece about the  It would do more or less exactly what the twitter.com website does. Same prefs, same commands, same user experience. Think Apache for the Twitter user interface.
It would do more or less exactly what the twitter.com website does. Same prefs, same commands, same user experience. Think Apache for the Twitter user interface.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}