The hideous entity that walks among us as “Paul Manafort” slips on its human skin-suit for a quick mugshot.#
Follow-up to yesterday's addition. Here's why it's interesting to put the RSS in the GitHub repo. You can see what changed. Of course that's what River5 is for. But it's interesting to see it in GitHub. Like many things on the net, both GitHub and RSS are about "what changed."#
- Here's a timeline. #
- Each news org should produce a list of news orgs they feel produce news that's not fake. Each should use whatever criteria they feel is right. Publish the list.#
- Evolve the lists over time. This problem is not going to be solved overnight. The process will take years to sort out. In the process we will learn a lot. If it works, it will transform news to make it much more useful because it's online and not print. #
- Techies, both companies and individuals, will build news products based on the feeds. For example, Facebook might offer a choice of news selected by different news orgs. An open source group could create software that flows Twitter-like news feeds from the lists. #
- This will become competitive. Some pubs' lists will fall out, others will rise to the top. There will be surprises. #
- Include blogs in the list, blogs that cover territory that you cover. For example, the NYT would include bloggers who cover neighborhoods. Tech pubs would include tech bloggers.#
- Include your entire news flow in your list. Amazingly some news orgs do not have a comprehensive list of every news article they publish in reverse-chronologic order. #
- You may choose to make your list a feature of your news site. You may also use other organizations lists as a feature on your news site. #
- Let's discuss our experiences at a future-of-news conference. After a few months' experience we should be ready to learn from each other. #
- This is not something tech companies can do for you. People whose work is producing news should come up with ideas for figuring out what is and isn't reliable news.#
- The canonical "fake news" site, Infowars, will of course produce their own list of reliable feeds. Totally valid. People who want to be informed by them may choose to do so. #
- One year ago today I introduced a feature that allowed me to include a post from Scripting News within another post. Here's the example, and the video demo. I wondered if I would use the feature. I haven't. But I forgot it was there, and forgot how it works. There's a CSS problem that's shown up, when I increased the size of the titles on the story pages. I'll fix that now.#
- This is a test. Breakage fixed. I changed the way permalinks to stories work. If an item has subs it's rendered on its own page. The URL will be different, so it has to be parsed differently when setting up the xref node. So this points to a story on its own page, and I'm going to work on the code to detect this and properly compute the location of its corresponding JSON file. #
- For the test above, the xref value is http://scripting.com/2018/07/09/143533.html#
- The JSON derived from that URL should be http://scripting.com/items/2018/07/09/a143533.json#
- This node is an xref. That means that in the OPML, it has an xref attribute, which is a link to a story on this blog. It's converted to the URL of a JSON file, which is then read, and included under this headline when it's expanded. #
{kind=link}
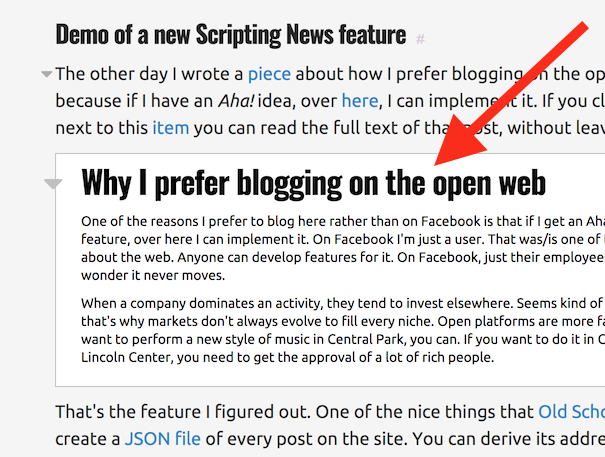
 After forcing a change to HTTPS, there are going to be other requirements. They'll try to eliminate fake news from the web as Facebook is trying (and failing) to eliminate it from their silo. That's the slippery slope they are starting down. They may not feel they have a lot to lose, but we do. Last year I wrote a piece about why I like to develop on the open web. If I get an idea for a feature, I can just do it. I could wait forever for Facebook, they don't listen to me (neither does Google) but I listen to me. I can do it without getting the approval of a big company -- that's the magic of an open platform. I will never give that up. I'd rather retire to Italy and make pottery and drink espresso and bubbly water. Grazie! #
After forcing a change to HTTPS, there are going to be other requirements. They'll try to eliminate fake news from the web as Facebook is trying (and failing) to eliminate it from their silo. That's the slippery slope they are starting down. They may not feel they have a lot to lose, but we do. Last year I wrote a piece about why I like to develop on the open web. If I get an idea for a feature, I can just do it. I could wait forever for Facebook, they don't listen to me (neither does Google) but I listen to me. I can do it without getting the approval of a big company -- that's the magic of an open platform. I will never give that up. I'd rather retire to Italy and make pottery and drink espresso and bubbly water. Grazie! #