The web still could be a fantastic writing environment.#
Some day all Americans will understand that our ancestors were slaves. #
An outline of my tweets for the last few days, with threads using the outline structure. I think this is a good way to have tweet streams flow into an outliner. Since it's entirely OPML and uses GitHub in a public repo, any outliner can be part of the network. #
Facebook is coming out with a Substack killer. Just guessing it comes with its own editor. Yet another crappy writing tool that doesn't peer with other writing tools. This is what kills the web as a writing environment. We should flush all these pieces of crap down the virtual toilet. If you're going to do something with text, please for writers' sake do not require them to use your stinking editor. #
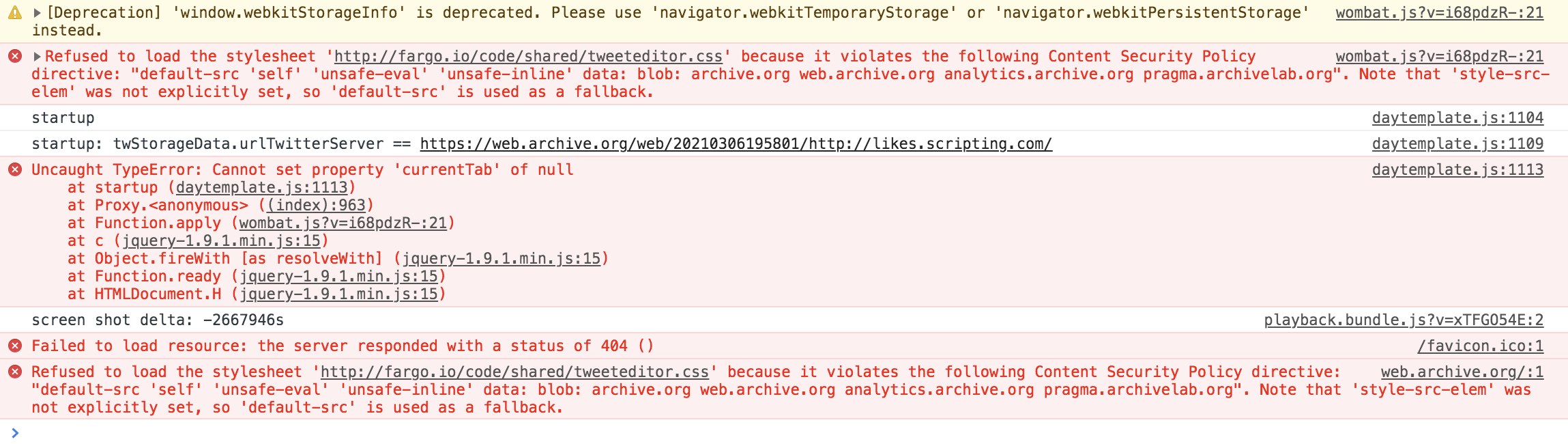
 I noticed yesterday that archive.org may not have a good record for this blog. When you go to one of their archive pages, the shell is visible -- the header graphic, title, footer, but the contents is missing. Screen shot. If you look in the console, there are errors. If you look at the actual page on the web, it looks fine. If a simple site like this blog can't be rendered by archive.org, perhaps we are making a mistake by depending on it as the record for what was said on the web. The question remains how do you maintain a record for a medium that thrives on its distributed nature that has a chance of lasting for decades or even centuries. The programmers at archive.org have an inhumanly impossible task, with all the experimentation on the web, over time, and like all programmers, they can make mistakes. Developers of websites make mistakes too -- a lot of the early UserLand sites are inaccessible via archive.org because they saw its crawler as a denial of service attack. Obviously our code was wrong, but there's no way to go back and fix the bug. The sites are long gone. #
I noticed yesterday that archive.org may not have a good record for this blog. When you go to one of their archive pages, the shell is visible -- the header graphic, title, footer, but the contents is missing. Screen shot. If you look in the console, there are errors. If you look at the actual page on the web, it looks fine. If a simple site like this blog can't be rendered by archive.org, perhaps we are making a mistake by depending on it as the record for what was said on the web. The question remains how do you maintain a record for a medium that thrives on its distributed nature that has a chance of lasting for decades or even centuries. The programmers at archive.org have an inhumanly impossible task, with all the experimentation on the web, over time, and like all programmers, they can make mistakes. Developers of websites make mistakes too -- a lot of the early UserLand sites are inaccessible via archive.org because they saw its crawler as a denial of service attack. Obviously our code was wrong, but there's no way to go back and fix the bug. The sites are long gone. #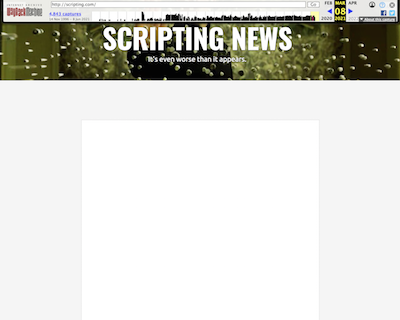{kind=link}
{kind=link}
TheTwoWayWeb.com appears to be well archived. "I want to turn the Web into a powerful and easy to use writing environment." I said that in 2001 and I still want to do it 20 years later." #