 About the author
About the author Dave Winer, 56, is a visiting scholar at NYU's Arthur L. Carter Journalism Institute and editor of the Scripting News weblog. He pioneered the development of weblogs, syndication (RSS), podcasting, outlining, and web content management software; former contributing editor at Wired Magazine, research fellow at Harvard Law School, entrepreneur, and investor in web media companies. A native New Yorker, he received a Master's in Computer Science from the University of Wisconsin, a Bachelor's in Mathematics from Tulane University and currently lives in New York City.
Dave Winer, 56, is a visiting scholar at NYU's Arthur L. Carter Journalism Institute and editor of the Scripting News weblog. He pioneered the development of weblogs, syndication (RSS), podcasting, outlining, and web content management software; former contributing editor at Wired Magazine, research fellow at Harvard Law School, entrepreneur, and investor in web media companies. A native New Yorker, he received a Master's in Computer Science from the University of Wisconsin, a Bachelor's in Mathematics from Tulane University and currently lives in New York City.
Contact meMy sitesRecent storiesRecent linksMy bike
CalendarWarning!

 Blocked from retweeting?
Blocked from retweeting? 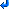
Earlier this evening I tried to retweet something, and got this message:
You have been blocked from retweeting this user's tweets at their request.
If you don't believe me, here's a screen shot.
{kind=link}
All kinds of thoughts come up.
1. I didn't know you could do that.
2. Is it in the user interface?
3. If not, how do you get this done?
 4. Why would someone want to do this?
4. Why would someone want to do this?
5. Retweeting seems pretty neutral. Not?
Anyway, I did a Google search and found it has come up before, so I'm not the only one. But not very often, which seems to indicate there is no user interface for it. Very odd.
BTW, "just blocking them" is not an answer, because a friend who I don't want to unfollow frequentlly RT's the person who has me blocked from RT'ing. If it gets annoying enough I guess I will have to unfollow the friend who I don't want to unfollow.
Also, it's that his tweets are private, they aren't. I am not following him. Another friend is retweeting them. Unless their "privacy" includes this feature, they aren't private.
In case it isn't obvious, Twitter is a morass of inconsistent rules about when it should and shouldn't show you stuff, and makes you block people when you have no interest in blocking them just to get another feature that comes along with blocking.
Apache plus Dropbox = Hello World
With all the money going into startups it's amazing that the underlying web isn't being built out.
 There have been some innovations in the basic web, the biggest in the last decade clearly is Dropbox, but even that is just a taste of nirvana. Their public folder is so incredibly useful. Amazing one of the hundreds of startups out there haven't seen fit to pick up that ball. Behind the scenes I've been urging Amazon and Rackspace to go there. Amazon's effort is so disappointing. They're such a great competent company. But they just don't understand the problem. I guess. Their product misses the mark, again and again.
There have been some innovations in the basic web, the biggest in the last decade clearly is Dropbox, but even that is just a taste of nirvana. Their public folder is so incredibly useful. Amazing one of the hundreds of startups out there haven't seen fit to pick up that ball. Behind the scenes I've been urging Amazon and Rackspace to go there. Amazon's effort is so disappointing. They're such a great competent company. But they just don't understand the problem. I guess. Their product misses the mark, again and again.
In a comment, Ryan Tate says: "It would be neat if someone combined S3's innovative pricing model with old-school Apache webhosting. Bonus points for supporting the S3 API."
I added of course that I want Dropbox too. And offered an explanation of why we're waiting so long. "The vendors aren't users." So many things waiting for this to be easy. It's as if the PC had been invented, but we were waiting for someone to create a word processor.
Update: An old friend from the dotcom days, Miko Matsumura, asks for a better explanation. Here goes..
I want to forget about running Apache. It should be a commodity. I want two ways to manage the content that's served for me by Apache. The S3 API, and Dropbox. I need a few of the features of htaccess files, the ability to specify my index file, error file, and to redirect permanently or temporarily. Maybe one or two other simple features. No dynamic bits. I pay for bandwidth and storage. Super-important that I pay. The hosting provider must be an entity whose longevity is obvious. Would be great to be able to pay in advance for 10, 25 or 100 years. As Ryan Tate says in a subsequent comment, with something like this in place, reliable, utility-level HTTP storage and serving, an industry could develop. One that, btw, would not be bubbly. Hope this explains it! ![]()
Can't run Scripting News on Amazon S3
 To review, Scripting News is mostly a static site with a few dynamic bits. All of them connected into the site via JavaScript includes. So theoretically the whole site could be moved into Amazon S3 using their new ability to specify an index file for a bucket (and it's sub-folders).
To review, Scripting News is mostly a static site with a few dynamic bits. All of them connected into the site via JavaScript includes. So theoretically the whole site could be moved into Amazon S3 using their new ability to specify an index file for a bucket (and it's sub-folders).
However, there are two problems, and I think the second one is a deal-stopper.
1. The inability to point scripting.com at the bucket. It must be a sub-domain because it must be a CNAME. I refuse to redirect scripting.com to www.scripting.com for religious reasons, although most others probably wouldn't mind. People I respect would. So I could use s3.scripting.com, which I kind of like. Anil Dash asked a question I hadn't thought of. You're putting someone else's brand on your site. Yeah. It's like "S3 brings you scripting.com." Seems they should have to pay for that. And further, it's an ad and I don't do ads here. But on the other side, it says very clearly to everyone who cares that this is an S3-hosted site, and so they know that if it works they should credit Amazon, and if it doesn't. Since this is a site with a large focus on people who develop for the web, it seems appropriate. So, all-in-all, this is an issue, there is no ideal solution, but there are workable ones.
2. Scattered through the folders are .htaccess files, that correct mistakes, glue the site to other sites, all around serve as a method of patching a site that's been around a long time, since 1994. There's a lot of that kind of patching in there. Of course S3 sees an .htaccess file as just another thing to serve up. So if I redirected scripting.com to s3.scripting.com, who knows what kind of hell would break loose. I don't remember all the things I patched this way over the years. I know the site works reasonably well. So I guess the bottom-line is that while I don't want to run Apache myself, this site needs to be served by Apache or something that emulates it. It seems that, unless I think of something else, S3 is for hosting new sites, not ones that have been around for a while.