 About the author
About the author Dave Winer, 56, is a visiting scholar at NYU's Arthur L. Carter Journalism Institute and editor of the Scripting News weblog. He pioneered the development of weblogs, syndication (RSS), podcasting, outlining, and web content management software; former contributing editor at Wired Magazine, research fellow at Harvard Law School, entrepreneur, and investor in web media companies. A native New Yorker, he received a Master's in Computer Science from the University of Wisconsin, a Bachelor's in Mathematics from Tulane University and currently lives in New York City.
Dave Winer, 56, is a visiting scholar at NYU's Arthur L. Carter Journalism Institute and editor of the Scripting News weblog. He pioneered the development of weblogs, syndication (RSS), podcasting, outlining, and web content management software; former contributing editor at Wired Magazine, research fellow at Harvard Law School, entrepreneur, and investor in web media companies. A native New Yorker, he received a Master's in Computer Science from the University of Wisconsin, a Bachelor's in Mathematics from Tulane University and currently lives in New York City.
Contact meMy sitesRecent storiesRecent linksMy bike
CalendarWarning!

 Ha ha ha April Fool ha ha ha
Ha ha ha April Fool ha ha ha 
Fool'd ya eh?
http://scripting.com/stories/2011/04/01/letter.html
It's also the 14th anniversary of the founding of a blog at www.scripting.com called Scripting News.
Can you find an earlier blog that's still updating? Let me know. No foolin.

Excellence in coffee
 Every once in a while, by accident, I brew an excellent pot of coffee.
Every once in a while, by accident, I brew an excellent pot of coffee.
Today, my dear friends, is one of those days.
What makes for excellence in coffee?
1. Good flavor.
2. Not too strong, but not weak.
3. No bitterness.
4. Very hot, even with a bit of milk.
5. A hint of sweetness of its own, with no sugar (I drink my coffee without sugar, always).
I suppose even if I could always make a perfect pot of coffee every time I wouldn't want to, because then there would be no cause to celebrate the days when the coffee comes with its own excellence.
It's like reading palms or tea leaves.
Is there a high correlation betw excellence in coffee and excellence in days?
Does a good cup of coffee make you want to do good?
Software end-game, like film editing
 It's been a while since I posted an update on the minimal blogging tool.
It's been a while since I posted an update on the minimal blogging tool.
The last couple of weeks have been really intense. Imagine my software is a movie and after editing the film and watching it a few times all of a sudden I thought of a different, better, plot. When I looked at the movie after figuring it out all I could think about was how much better it would be with the new ending. So I went back to the cutting table and luckily I only needed to re-shoot a few scenes and after much head-scratching and fights with the actors, the movie is back in one piece, and it's feeling like a classic.
Still a little rough in places, but we'll work those out.
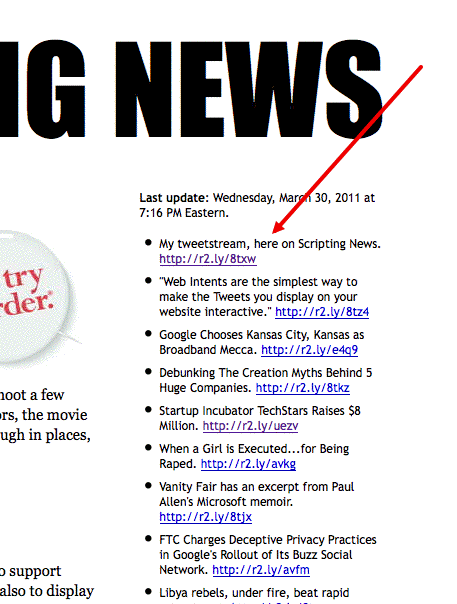
My tweetstream, here on Scripting News
It's time to test a new feature. I want Scripting News not only to support long-form blogging, posts like the one you're reading now, but also to display the link-blogging I do. The stuff that normally flows out to Twitter (and still does, of course).
So I put together a little snippet of code that every time I post something new, rebuilds a bit of Javascript that displays the last 20 linkblog entries as an HTML list. Thus:
<script type="text/javascript" src="http://static.reallysimple.org/users /dave/linkblogxml/miniLinkBlog.js"></script>
Here's a screen shot illustrating what it looks like on the home page. (I'm leaving the story pages uncluttered for now.)
Rebooting the News today at Noon Eastern
Another Rebooting the News today at noon Eastern.
We're going to do a live stream, again, on Talkshoe.
Please come listen if you're around.
I'll post the MP3 here when we're done. ![]()
![]()
Are you buying into the Times paywall?
 Today is the day I thought would never come -- the NY Times is turning on its paywall for the rest of the world (Canada got it last week).
Today is the day I thought would never come -- the NY Times is turning on its paywall for the rest of the world (Canada got it last week).
I haven't received a pitch from them, beyond getting a free account for the rest of the year from Lincoln. Not sure who else got that offer. Could be the Times gave that to everyone they thought might be vocally against the paywall? Or might feel the pain and complain publicly?
Or maybe they just want me to read their stuff and decided that a little money between friends is kind of crass. (I wish Apple would give me some free hardware on that basis. Often felt I deserved a little shout out from them. What ever.)
So the big question is -- what are you going to do today?
Is it a bubble? It matters if we think it is.
 Every day more people ask if this is a bubble. Some say yes, some no. Those that say no seem to say it with hesitation. It could be my imagination, but it seems those who say yes say it with less.
Every day more people ask if this is a bubble. Some say yes, some no. Those that say no seem to say it with hesitation. It could be my imagination, but it seems those who say yes say it with less.
It matters whether we think it is a bubble, because the day there is a consensus that it is, it will have popped. And then we will be in the post-bubble world. So what? A few rich investors will lose billions. If they're smart they're already hedging. They might lose billions after making more billions.
The people to worry about are the entrepreneurs and their employees, because this time there are many more of them (despite this misleading chart in the NYT today). In this bubble there's a long tail of individuals starting companies. And they're almost all very young, and probably don't have a cushion to ride on through the inevitable downturn.
 The last tech bubble burst really hit the people hard. And this time, because it's had more time to inflate and because it's built around user generated content, the failures will have a wider impact, again on people, and on the web.
The last tech bubble burst really hit the people hard. And this time, because it's had more time to inflate and because it's built around user generated content, the failures will have a wider impact, again on people, and on the web.
The winners are going to be people who have cash-generating businesses. And users who, instead of accepting the illusion of free web services, didn't cut corners and are using servers they control. Because as the companies caught in the downturn look for ways to monetize, their silos will have fewer openings and they'll be higher up, further out of reach. Pity the businesses that built on the assumption that Facebook and Twitter would always host their presence on favorable terms. Those are variables whose value will be different after the bubble pops.
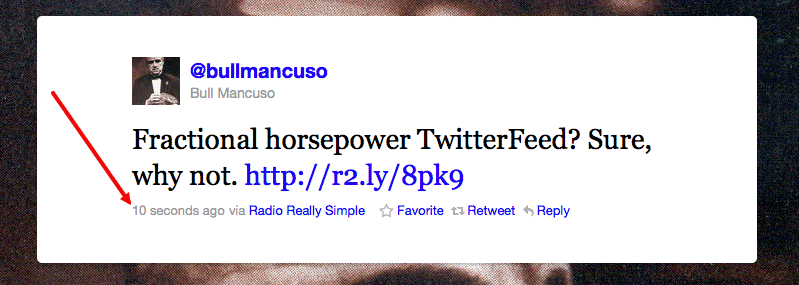
Fractional horsepower TwitterFeed? Sure, why not.
 A few years ago I wrote about a fractional horsepower web server.
A few years ago I wrote about a fractional horsepower web server.
Then in 2009, about fractional horsepower Twitters (which we're getting mighty close to now in 2011).
You can also see what we're working on as a fractional horsepower news network.
"Fractional horsepower" is a Steve Jobs idea, and it's a good one. Before he came out with his fractional horsepower computer, also known as the Apple II, computers were thought to be big things that few people could manage, and had limited applications. These days we carry more computing power in our pockets than the data center I learned how to program in had. But they still feel small and personal.
There aren't many things that can't benefit from being fractionalized.
Anyway, one of the big components of the system I'm working on is TwitterFeed, or something like it. It maps a feed onto a Twitter account. The problem is it takes up to 1/2 hour for it to recognize something new has published to my feed. That's okay for me, I really don't mind. But I don't imagine too many users buying into that. We simply had to get it faster.
Sigh.
That's the feeling I had this morning, when I decided to dust off my OAuth code and write my own bridge, one that would watch over a few hundred feeds, and provide instant connections using rssCloud.
 Let me say this right now: OAuth is a bitch.
Let me say this right now: OAuth is a bitch.
A nasty ugly ornery hellacious mean-spirited unfaithful, venge-filled, hate-filled Nazi bitch.
Another way of saying the same thing: OAuth has no honor.
Every time I pick it up it's broken, and I spend five hours wrestling it back into its box. And while I was doing it, reading the Twitter docs that say this is deprecated and that is depreciated -- etc. So I know in a few months all this shit is going to break too. This is why I wanted to let TwitterFeed worry about it. And I still would like to do that.
But for now, I've got a test server running, moving all my linkblog posts to my test account on Twitter. I'll tell you this, when I see how fast it is, I forget about how much time I've wasted coding OAuth.
An Internet inside an Internet
 Dropbox is amazing, more amazing than I realized. It solves so many problems that I was waiting for a solution to. But sometimes you have to flip around the way you think about the problem to see that.
Dropbox is amazing, more amazing than I realized. It solves so many problems that I was waiting for a solution to. But sometimes you have to flip around the way you think about the problem to see that.
For example, I wanted WordPress to give me a way to store the source code of a WordPress blog post. Then I realized today that I could store the source in my public Dropbox folder and just render it on WordPress. Hey it would be best if the blog could be self-contained, but this wouldn't be too bad.
Then I remembered the work we were doing with the World Outline, and how we needed everyone to own some web storage for it to work. Just a place to put some static XML files. I put that problem down because because of that limit. Well, it's time to pick it up again.
There's also S3, which makes a whole bunch of other, similar things possible, if you assume all your users have accounts there. Well, with EC2-for-Poets, which is coming along wonderfully -- all the users do have S3 accounts. So I store each user's cache in S3 space. It's quite fast. And with the JSON architecture we're using now for rivers and user interface, you can use S3 almost as if it were RAM. In fact, I kind of do. ![]()
Read an article that says Amazon has everything lined up to do a tablet. They also have everything lined up to be something much bigger.
There's a new kind of software coming online. Just beginning to see the outlines of it. This is the kind of work I live to do. This is exactly where I like to be.
It feels like a new Internet is springing to life inside a corner of the Internet. It's like opening a jewel box and finding a universe in there.
Pics feed
I need a feed with pics for testing. Here it is.
http://static.scripting.com/randompic/rss.xml
When it's finished it'll pub a new pic every 10 minutes.
PS: It's finished. ![]()

Here comes the "social camera"
Everyone is focusing on the $41 million that Color raised, but thanks to Tanomsak for pointing out that it is very close to the Social Camera I was asking for in June 2007. Worth noting.
 So there's a use-case for this product that they're not promoting -- when you're traveling, now you'll be in the pictures you bring home, if enough people around you have this app.
So there's a use-case for this product that they're not promoting -- when you're traveling, now you'll be in the pictures you bring home, if enough people around you have this app.
Also you all should thank me for preventing a nasty patent, although it's pretty likely the company has already filed an application, don't you think? But there's the product described in a blog post four years ago. Makes it hard to claim it as a non-obvious invention. ![]()
PS: To people who say you have to be in your 20s to understand today's technology, here's some pretty convincing proof that's not true. In 2007, I was 52 years old, when I had this $41 million idea. If you're only betting on 20-somethings, you're missing out on a lot of goodness.
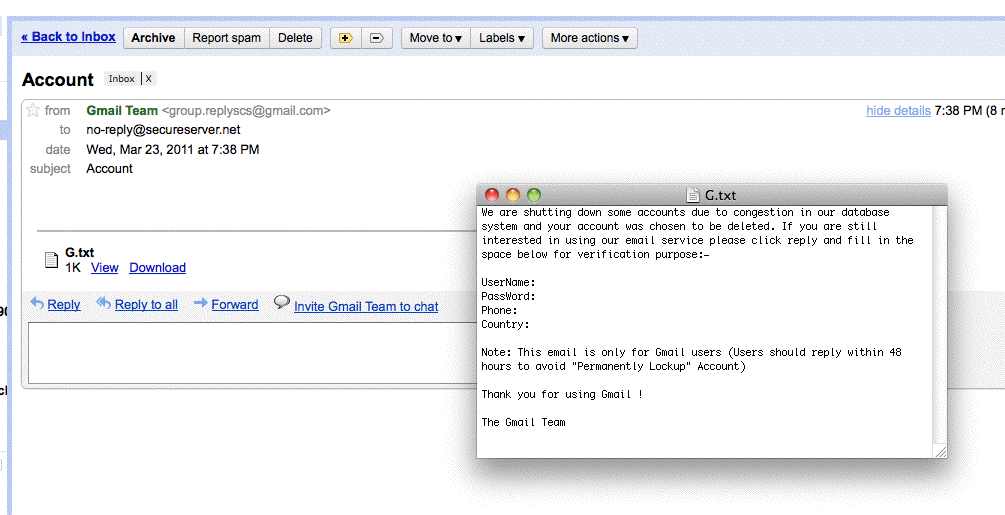
Nasty gmail phish
Here's a screen shot of an email that got through GMail's spam filter.
"We are shutting down some accounts due to congestion in our database system and your account was chosen to be deleted. If you are still interested in using our email service please click reply and fill in the space below for verification purpose."
It almost looks official, and it came into my Inbox, not the Spam box.
None of you guys would fall for this, but keep an eye out for friends and relatives. ![]()
Deprecated by Google?
I got an email yesterday from longtime friend Lance Knobel that the excellent Berkeleyside blog has been removed from Google News. I guess this is not a small issue for them, nor is it for Berkeley, which now has exactly two tiny news organizations reporting its news. Berkeleyside is one of them.
And they're doing a first-rate job. I don't live in Berkeley any longer, but I still subscribe, and regularly push links to their stories in my feed, because they're so well-written and interesting.
I've also noticed that searching for pieces on Scripting News has all of a sudden become hit-or-miss as well. It used to be that Google adored blogs, and we got special treatment. Now it seems the other way. Interestingly if I post a link to a story here in a Google Group that appears to be more likely to be caught by Google than a story on the main site.
 Now of course it's Google's right to do as they please with their search engine. I haven't monetized this site, so I can't say I'm losing money, I'm not. But had become something I depend on. I've even built systems around the assumption that Google will quickly index my stuff. And it could be my fault, maybe there's something wrong with my sitemaps, or maybe I'm not very well SEO-ized. Or it could be that my blog, for some reason, looks like one of those artificial content mills with billions of pages pointing at each other trying to trick Google into giving them more juice. It's possible that it looks that way, but I assure you it is hand-written from the Mind of Dave.
Now of course it's Google's right to do as they please with their search engine. I haven't monetized this site, so I can't say I'm losing money, I'm not. But had become something I depend on. I've even built systems around the assumption that Google will quickly index my stuff. And it could be my fault, maybe there's something wrong with my sitemaps, or maybe I'm not very well SEO-ized. Or it could be that my blog, for some reason, looks like one of those artificial content mills with billions of pages pointing at each other trying to trick Google into giving them more juice. It's possible that it looks that way, but I assure you it is hand-written from the Mind of Dave. ![]()
But I will say that if this is a permanent thing, and not in my imagination (could be!) there might be an opportunity for a search engine that loves blogs to position relative to Google.
Advice for newbie OPML programmers
 Last night I gave Ted Howard a bit of grief (in hopefully a friendly way) on writing code to connect two components running in the OPML Editor. But I didn't say how to do it.
Last night I gave Ted Howard a bit of grief (in hopefully a friendly way) on writing code to connect two components running in the OPML Editor. But I didn't say how to do it.
I wondered how I would approach it if I were completely new to this environment. There are quite a few ways to write a background process that glues two components together. If it were random, I'd probably pick a way to do it that wasn't very supportable. I might even choose a way to do it that is broken! :-(
Then I asked myself how I want him to do it. What would be the easiest to maintain as we go forward. And for that, there is absolutely no question what's the right answer.
WRITE A TOOL.
I put that in capital letters and boldfaced it because it is the absolutely number one best answer for any bit of code you want to write to run in the OPML Editor. It's also a good place to start exploring, because all the power of the environment has been encapsulated. You just put the code in the right place and it'll run once a minute, hour or overnight. Or in a background thread. Or as a web page. Or... etc etc.
A number of years ago (probably a depressingly large number) we put together the Tools framework for writing apps that run in Frontier. And we even documented it. ![]()
http://frontier.userland.com/tools
And for the most part it hasn't changed. A tool written ten years ago for Frontier or Radio, will likely still run in the OPML Editor today.
Everything I write is a tool, so you know they aren't going to break, at least not on my watch. And if there's a bit of functionality you need that isn't there, this is the place I would like to add it. Because it will make my programming life easier too.
Another reason to write a Tool is you may want to share it with others, and if you do, they will likely know how to use it.
Update: An excellent up-to-date tutorial on Tools by Andy Sylvester.
Call for startup: Easy domain editing
This is the first in a series of blog posts I'm going to write that define a opportunities for startups.
 In all cases, these startups will have a business model that revolves around an old-fashioned idea that will, imho, once again become fashionable -- the customer. People pay the company for a service they provide. This has all kinds of good side-effects. We'll see customer-driven products, ones designed to serve users, instead of some vague idea of a marketer that can sell things to the users. It will foster competition to serve users. It will help the economy straighten itself out and start creating products with obvious utility. Most of the scams that are supposed to be businesses turn out to not be all that lucrative anyway.
In all cases, these startups will have a business model that revolves around an old-fashioned idea that will, imho, once again become fashionable -- the customer. People pay the company for a service they provide. This has all kinds of good side-effects. We'll see customer-driven products, ones designed to serve users, instead of some vague idea of a marketer that can sell things to the users. It will foster competition to serve users. It will help the economy straighten itself out and start creating products with obvious utility. Most of the scams that are supposed to be businesses turn out to not be all that lucrative anyway.
Okay enough preamble.
Everyone wants a way to associate a name with a net resource. We've been arguing about this for a long time. Yet, all the time we're debating, we're using one that works perfectly well, operates at Internet scale, and has a proven business model that generates real money. It's called the Domain Name System. Each of us is using it hundreds if not thousands of times an hour while we surf the net, write code, play Angry Birds or Words-With-Friends.
It's so obvious, so everywhere that pundits don't even bother saying it's dead. It's so pervasive -- it's the Super-Dead. The VCs don't understand it, they don't see it, that's how dead it is. ![]()
Even so, we need a web service that makes it easy for people to:
1. Buy a domain.
2. Give a sub-domain to a friend.
3. Charge someone to use a sub-domain.
4. Manage sub-domains.
A good designer could come up with a browser-based editor, it seems to me, fairly quickly. Even better, Amazon now offers a web service that allows you to manage domains and sub-domains. Iterate over the design to take out every gotcha, every unnecessary concept, to make it accessible to as many people as possible. And fast. 1-2-3. In and out quick.
Setting up a sub-domain must be as easy as signing up for Twitter or Facebook, or buying a shirt on Amazon.
The only part of this deal that isn't simple is #1, and that's largely a bizdev thing. Get 2-4 going, and then we'll find an existing registrar to merge with. And off to moon! ![]()
I would love to be an adviser to such a startup, in return for options (of course). The software I'm building absolutely needs this service and I would recommend a good implementation, even if I weren't an investor.
October 13, 1994
Over the weekend, a reporter emailed asking when I started blogging.
Short answer: October 13, 1994.
 If you look at the chronology of DaveNet, you'll see it wasn't the first piece, it was the third. But it was the first I wrote after realizing that I could publish my ideas on the Internet, without going through a publisher. The two pieces before that were more like notices or ads. This one was meant to stimulate thinking among people who were reading. And boy did it ever stimulate thinking! What came back was a virtual avalanche of ideas, from some very smart people. I published the most interesting response (to me at least), back out through the same channel. And then I did it again, and again, and on and on. I'm still doing it almost 17 years later.
If you look at the chronology of DaveNet, you'll see it wasn't the first piece, it was the third. But it was the first I wrote after realizing that I could publish my ideas on the Internet, without going through a publisher. The two pieces before that were more like notices or ads. This one was meant to stimulate thinking among people who were reading. And boy did it ever stimulate thinking! What came back was a virtual avalanche of ideas, from some very smart people. I published the most interesting response (to me at least), back out through the same channel. And then I did it again, and again, and on and on. I'm still doing it almost 17 years later. ![]()
I'm sure people will dispute that date, it's the nature of blogging to dispute things. But I was there, and you probably weren't. And from that point on, it was a sequence of steps that eventually led to all the things we consider part of blogging today.
Some people who have studied this stuff minimize the ideation process, the evolution of blogging from virtual nothingness to a literary practice (at its best) that's capable of delivering great insight and feeling. If you doubt me, look at Nobel laureate Paul Krugman's dispatch of former Fed chairman Alan Greenspan. That's a bit of on-the-record writing that belongs in a history book. And it was written in the last 24 hours. The freshness and directness are, to me, the best of blogging.
Designing software is hard work. The things that seem obvious after-the-fact were anything but obvious before. The best things, the most useful innovations, are the ones that seem so obvious later that they melt into the fabric of reality and become invisible. I am proud to say that many of the things that came from the evolution of blogging have turned out that way. Like all art, software design strives for suspension of disbelief. In our world, that effect is felt by the tools becoming so invisible that you can focus all your attention on your work. It's creativity for the sake of other creativity.
There are other milestones for sure. I remember the frustration of the flaming mail list for the 24 Hours project and realizing I could side-step the flamage by publishing a reverse-chronologic list of links to pieces of the project. In other words, a link-blog.
After that, came Frontier News, a link-blog for a scripting community. Which then led to Scripting News, and that blog is still running today. But the beginning, the first blog post authored by yours truly, was the open letter to Jim Cannavino on October 13, 1994.
PS: Why I don't do interviews, in a blog post, of course. ![]()
What Twitter and the NYT have in common
Reading this survey of Twitter's QuickBar, and having read a dozen articles about the Times paywall (and written one of my own), there was something eerily familiar about the QuickBar story. Didn't take long to figure it out.
Neither company has a way to sustain itself finanically.
Not only that, they don't have any ideas.
The difference between the Times and Twitter is that we've known that about the Times for a long time, and only suspected it about Twitter.
 I think it's pretty unfortunate that these companies are taking chances with the parts of their systems that work to cover up for the fact that they have no clue how to be a business in their respective futures.
I think it's pretty unfortunate that these companies are taking chances with the parts of their systems that work to cover up for the fact that they have no clue how to be a business in their respective futures.
Funny thing is, they're like ships passing in the night. Each is the solution to the others' problem. ![]()
BTW, one obvious idea for Twitter to make money that I've not heard discussed is simply let us pay to ease up from the 140-character limit. Let's say the new limit is 256 characters, but you have to pay $2 per year per character. So if you can only afford $50, your limit will be 165 characters. To go all the way to the max would be 2 * (256 - 140) or $232. I bet NPR would kill to have such a premium to offer.
Question for the NYT
 I understand that links from Twitter and Facebook will pass through the paywall. As readers of this site know, I am preparing tools that route-around these Corporate Blogging Silos. I simply publish my links through RSS and depend on TwitterFeed to push them to Twitter. And the links should flow everywhere else, because RSS is so widely understood.
I understand that links from Twitter and Facebook will pass through the paywall. As readers of this site know, I am preparing tools that route-around these Corporate Blogging Silos. I simply publish my links through RSS and depend on TwitterFeed to push them to Twitter. And the links should flow everywhere else, because RSS is so widely understood.
I hope to encourage many more people to do the same, and I think they will want to, as Twitter becomes more restrictive. I think this is in everyone's interest, except perhaps the owners of the CBS's. I believe independent publishers like the Times will eventually come to appreciate that there are options that don't flow through bottlenecks created by the tech industry.
So here's the question. Is the Times going to encourage people to stay inside the silos by only offering special access to them, and not to people use systems that are not siloed?
Update: Mark Cooper says "all links will pass through the paywall."
We should invest in public broadcasting
 I have a fairly unique position to view this, as one of a small number of people who pushed podcasting forward 10 years ago (the anniversary was in December).
I have a fairly unique position to view this, as one of a small number of people who pushed podcasting forward 10 years ago (the anniversary was in December).
It's a long story, but NPR's support, starting with Tony Kahn and WGBH, was crucial. I don't think it would have reached liftoff it weren't for their involvement.
And they were able to participate because they are non-commercial. Commercial radio couldn't have played the same role.
We need to have more media that isn't corporate. We also need more programmers who aren't but that's another story.
Anyway, when the next technology like podcasting comes along, we're going to want to have a media organization that can afford to experiment.
Maybe the tech industry can pool its resources and come up with the money the US government isn't allocating. It would, imho, be a good investment. Really not very much money when you consider how much is being poured into random startups, and what can be built off this kind of experimentation.
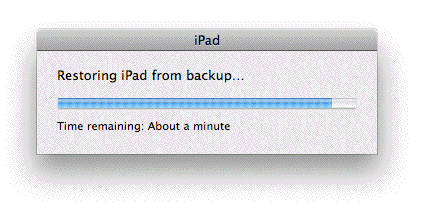
My iPad arrived
 When there's a problem with an Apple product, get ready to deal with super assholes. They gravitate to Apple. Always have and always will. With that in mind, I'm going to tell you what happened when I plugged my new iPad into my Mac. I'm just going to tell you what happened. I don't care if the assholes swoop in and are asshole-like.
When there's a problem with an Apple product, get ready to deal with super assholes. They gravitate to Apple. Always have and always will. With that in mind, I'm going to tell you what happened when I plugged my new iPad into my Mac. I'm just going to tell you what happened. I don't care if the assholes swoop in and are asshole-like. ![]()
I checked in the middle of the night, the Fedex tracking report said it had just left Anchorage. By the time I was at work at 10AM, it had been delivered. Went downstairs to get it, took a picture, upgraded iTunes. Connected my old iPad. Connected the new one. It asked if I wanted to clone the old one or start anew, I said clone it. Took five minutes. Booted up. Whoa, where are my apps? There are a few new ones. But the old ones are gone. Disconnected. Reconnected. Says it's synching. Backing up.
Ahhh. It looks like you have to specifically choose to synch Apps. That's what it's doing now. Makes no sense. I already said clone it.
Now more of the apps are there, but not all of them. It doesn't seem to have synched the Kindle app. It's one of my most-used. Or Words With Friends, or the various versions of Angry Birds I have been using. What is going on here? (I can hear some Apple idiot saying "It worked for me.")
Now I see what's going on. They put all their apps on the first two screens, and my apps come after that.
Tried using the Kindle app and it wants me to re-register. I hope they're not all going to be like this. (Yes, it has forgotten all the passwords. For everything. Arrgh.)
And all the apps I paid for are missing. This is ridiculous. If they said when you get a new iPad you have to re-buy all the apps you use, well, I wouldn't have bought a new iPad. Getting a new toy is supposed to be fun. What about the games I was in the middle of, and the books I was reading. Places lost in all of them. Still hoping there's something I can do to just copy the whole iPad 1 to the new iPad 2 so I can avoid all this. I don't want to send the new one back. Really don't.
Further, I don't dare plug the old iPad into iTunes for fear that it will do the same thing to it that it did to the new one.
According to the commenters this is a common experience. You often have to re-download your apps when upgrading to something new from Apple. And if that doesn't work, you get to "contact customer service." As if my time were worth nothing. I honestly don't see any of that happening. And forgive me, but I'm totally disappointed this thing didn't "just work" -- I thought that was Apple's business model.
New approach.
1. I'm wiping the new iPad.
2. Just did a backup of the old one. (Summoned my courage and it didn't seem to kill it.)
3. Going to try to restore the new iPad from the backup of the old one.
4. BTW, the reason you don't want to start over with these things is games like Angry Birds make you start over at the beginning, slogging your way through the beginner stuff. And there's lots of that. I had completed every level and was working on getting to three stars on all the latest stuff.
Finished doing the restore, I'm going to let it sit for a while per Joseph Rosario's recommendation, but it appears nothing is different. My guess is that they don't back up the for-pay apps, that's why you get the weird dialog when you back up your iPad saying you have paid-for apps on it. I always wonder why they needed to tell me that, now I know. All I get are the worthless crap apps I didn't want, and none of the apps that I decided to use and therefore was willing to buy the premium version of. Now I have to remember what they all are and hope they really let me re-download them. All this I guess is supposed to prevent piracy, but I'm not sure how that works. The old copies are still on the iPad I cloned. So I will, when it's all over, have two copies I can use. Unless somehow they deauthorize the other copy. I bet they do.
I think that's where we're going to leave it. Yes I am installing all the purchased apps, at least the ones I can remember that I purchased. The good news is that it remembered where I was in each of the games. I have a move to respond to in Words With Friends. But they made me work way too hard, spoiled the first-time experience. On the other hand I had some fun at the expense of with Apple zealots. ![]()
s3.scripting.com
Trying an experiment overnight when the traffic is low.
I'm redirecting from scripting.com to s3.scripting.com.
I'm using a code 302, non-permanent redirect, so if things break badly I can easily go back.
I'm wondering if I can switch over to S3 for static hosting. The only way to find out for sure is to try it and see what happens.
![]()
Update: The experiment didn't work. Too many redirects. I don't think Apache sites, even static ones, can be moved into S3 space. Not unless they never did any kind of redirecting to hold it together. This site has been around since the mid-90s. Too much history I'm afraid. :-(
JSONified RSS
 I spent the last couple of days creating an installable scripting2.root, with a howto. That's the software I use to edit this weblog and produce all the feeds.
I spent the last couple of days creating an installable scripting2.root, with a howto. That's the software I use to edit this weblog and produce all the feeds.
The sites are fully baked, meaning they can be hosted anywhere. It's set up to, by default, host sites on Amazon S3.
One of the things I tripped over while testing the release is some code I forgot I had written. It manages a file that's what I think of as JSONified RSS. It's the feed for Scripting News rendered as JSON.
From this, I believe you could create a JavaScript browser for this kind of website. Not sure, but I think it could be interesting.
My dream would be to have the Readability guys take a shot at this. Or Flipboard. Hmmm. ![]()
PS: The server you get with EC2-for-Poets will run scripting2.root just fine. The pieces are starting to fit together real nice.
Tweeting about Twitter's Terms
There's a lot of tweeting going on about Twitter's terms of use for the API.
Not sure what's new, I don't pay close attention. But the focus seems to be on Section I, paragraph 5, sub-E.
"You may not use Twitter Content or other data collected from end users of your Client to create or maintain a separate status update or social network database or service."

What this seems to mean is:
1. If your client touches the Twitter API, then any text or data the user enters into that app becomes Twitter Content.
2. You cannot use that data to form a new service. So there goes the idea of Twitter clients sharing info between each other using RSS. They should have done it a long time ago, now they would be able to fall back on that net (and that's why Twitter wouldn't be able to pull this string now).
3. You can't be half in and half out. Either you connect to Twitter, and they own you and your users, or you don't connect to Twitter.
I don't think there's really anything here that wasn't obviously coming before. I've said it many times, but I guess people don't read my posts, otherwise why are they surprised. This has been a long time coming.
Comments on NYT paywall announcement
 I had a pretty strong feeling the announcement was coming when I wrote the piece about the Times paywall yesterday.
I had a pretty strong feeling the announcement was coming when I wrote the piece about the Times paywall yesterday.
Now that I've had a chance to read the actual announcement, here's the problem. They're not offering anything to readers other than the Times' survival, and they're not even explicit about that.
Wouldn't it have been wise to, at this juncture, offer something to sweeten the deal. Something truly exciting and new that you get when you pay the money. Something that makes your palms sweat and your heart beat faster?
I put down $700 last week to get a few minor improvements to my iPad. If they had said "Give us $700 so we can survive," well, I might have done it. But I feel better about getting the new features. ![]()
The mistake is not viewing this from the other end of the communication pipe. Listen to to the pitch from the other guy's point of view. This is the same thing NPR fails to do in their pledge drives. I suppose it's in the nature of the old way of doing news. Our job is to appreciate and pay and their job is to inform and be paid. Of course even NPR would acknowledge that isn't how news works anymore. Maybe even some people at the Times would, today. More will in the future.
Now would have been a very good time to turn the formula around, show a little vision beyond "We need this to survive."
I'd like to hear something that makes me believe they are excited about the future news, and are translating that excitement into thoughtful new products.
On the other hand, they did something smart in not charging readers who get to a Times story through a link from a blog post or tweet. But -- since I am a frequent linker, I wonder why I should pay to read their site, when I'm delivering flow to them. How does that equation balance by me paying them? Maybe they should pay me? Seriously. I have a need to survive too.
As always comments are on the record and for attribution. I am editor of Scripting News, visiting scholar at NYU in journalism, and a leading software developer.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Test-post-plus
 This is both a test post and a celebratory post (if it works).
This is both a test post and a celebratory post (if it works).
Yehi! It worked. What this means is that I now have scripting2.root as an installable tool, just like Radio2 and River2.
Here's a post with an admittedly ugly URL.
But it illustrates something that Werner Vogels will probably like, Jeff Barr too. Out of the box this tool likes to create blogs on S3.
Flip it around, what's becoming clear is that S3 makes storage easier, and that may be enough to make it worth another try for people hosting their own blogging software. We've done that with Radio2 which is a lightweight microblog editor, and now we have the same idea working for the heavy duty professional blogging solution, Scripting2 (the software I use to edit Scripting News, completely rewritten last year).
If you don't understand what any of this means, stay tuned. This is just a test post. ![]()
A new feature of RSS
What's that -- a new feature? But I thought RSS was frozen.
Yeah it's frozen, but a new feature is still always only a namespace away.
{kind=link}
I wrote about the microblog namespace in Twitter Posts Don't Have Titles, a subject that could only interest someone who has been puzzling over how to do a Twitter-like streamer using RSS as the transport. The problem isn't whether or not RSS can do it, it can, the question is what to do about feed readers that don't understand. Answer: Let em figure it out! ![]()
In the meantime, I thought it was time to add some long-needed stuff to RSS, in a namespace of course.
For example, a lot of people wonder whatever became of their tweets. I have over 30,000 of them. Most of them are gone, poof -- into the ether. But some of them I have archived. I am determined that whatever we boot up now have archives provided for, in the base model.
So if you look at my linkblog feed you'll see an item called <microblog:archive>. Here's a screen grab.
{kind=link}
With that info, you can loop over all the items I've pushed through this feed, going back to its inception. That's a built-in feature of Radio2. All Radio2 blogs have this feature.
So there's an advantage that microblogs outside-the-silo have over insiders.
Will we see the NY Times paywall soon?
Amid revolutions and huge earthquakes and nuclear meltdowns, we're reminded that we might see a NY Times paywall any day now.
I've always said that the Times likes to talk about a paywall, and they've been doing that for a long time, but when it comes time to put it up they'll realize it cuts them off from the world, and they won't do it. It's like a baseball player refusing to get on a baseball field. Once you do that you stop being a baseball player.
But then corporations are capable of doing things you never thought they could possibly ever really do, when it came down to actually doing it.
1. Microsoft insisting that all netbooks had to run Windows 7. I figured they wouldn't mess with a good thing and would let the OS fade into the background. Here was a chance to create some new software because netbooks could be used in places no other computer could have been used before -- because of price, battery life and built-in communications. But they did manage to remove all the excitement out of the netbook product, just in time for one of the most exciting products ever, the iPad -- to swamp it.
 2. Twitter and the coral reef. I think they really didn't see all the consequences as they drifted toward the model they now find themselves in. One where, in order to get revenue they had to shut down almost all the developers. The decision they announced on Friday was both impossible and inevitable. It was impossible to believe they could actuallly do it, and inevitable because they had no choice. I wonder if the founders of the company don't now wish they had gone a different way, one where Twitter could become an indispensible new layer to the Internet, instead of a bigger and bigger obstacle to that layer, to be routed around. I don't think in the end the founders will make much more money this way. The difference is that they bring along some very greedy people, who don't mind foreclosing on huge amounts of creativity to make a relatively small amount of money.
2. Twitter and the coral reef. I think they really didn't see all the consequences as they drifted toward the model they now find themselves in. One where, in order to get revenue they had to shut down almost all the developers. The decision they announced on Friday was both impossible and inevitable. It was impossible to believe they could actuallly do it, and inevitable because they had no choice. I wonder if the founders of the company don't now wish they had gone a different way, one where Twitter could become an indispensible new layer to the Internet, instead of a bigger and bigger obstacle to that layer, to be routed around. I don't think in the end the founders will make much more money this way. The difference is that they bring along some very greedy people, who don't mind foreclosing on huge amounts of creativity to make a relatively small amount of money.
Meanwhile the Times app on the iPad is slow and crashy and incomprehensible. You can't get a quick sense of what's going on in the world. Using the news in this environment is a lot like it was in the 70s and 80s. Sit down at the kitchen table, spread out the newspaper, and spend an hour reading. As with the NewsCorp product, they seem to be saying "If we put a lot of effort into this we can convince people to use written news the way they used to." They could skip it, because things like that don't happen.
But they could do it anyway. If they really think people are going to pay a premium for a lugubrious daily news product, they're going to be as surprised as Microsoft and Twitter. There are too many choices. The Guardian is doing great work and there's no talk of a paywall there. They're not as broad as the Times, yet -- and they cover the world from a British perspective, and I look at things as an American. And there's Al Jazeera, which is aggressive and competent, and probably would move quickly to fill any void left by an entity the size of the Times.
I link to the Times in my feed probably more than any other publication. I might soon have to give that up. Oh well. I stopped using my netbook too. ![]()
Goodnight Zune
Noted: Zune is no more.
Oy. What if. If only.. Told. You. So.
Zune was the worst idea ever. They could have zigged to Apple's zag. Apple built a fantastic music playing device. Zune could have made the best podcast player. There is a huge difference between the two forms.
1. You buy a song, a podcast is free.
2. You listen to songs many times, a podcast is listened to once.
3. You keep a song, you throw out a podcast.
4. I don't know about you but when I replay a song I want to start at the beginning. But if I haven't finished a podcast, I want to resume where I left off.
5. You make lists of songs, you curate them, put them next to other songs, sing them, hum them, can't get them out of your head, listen to them years later and they bring back memories. You do none of that with podcasts.
But podcasts are great! I'm going for a walk now and I will get caught up on nuclear power and listen to an interview with Dr. John (there's the connection to music, btw).
We, who love podcasts, still make-do with the iPod when we should have a great podcast player. Now maybe podcasting isn't such a huge market, but maybe it would be if it had been inspired by a device made specially for podcasts? You never know! ![]()
Another what if...
What if Microsoft had said FUCK YES! to netbooks instead of "Oh well if you insist we'll let you use Windows, but you have to cripple the hardware, and when we ship Windows 7 you have to use that even though there's negative demand for it."
What a mistake to waste the two-three year head-start they had over Apple. They should have been blown away by the new demand for Windows as a mass market thing and helped the netbook makers come up with ideal form-factors, even subsidized the sales, all to capture a mobile market that they could use as a beachead to compete with Apple. Instead they're left doing a dead-leading-the-dead deal with Nokia.
Ballmer is a sales guy. Maybe he's a great one, I don't know. But he's completely outclassed as a product strategist by Jobs. And Microsoft should finally let go all those Windows coders, if they haven't already done so. They need to become a distributor and investment banker, and stop trying to compete in areas they clearly can't. And if they ever get so lucky as to have a phenomenon like netbooks land in their lap, don't let it slip away by being all corporate.
Twitter posts don't have titles
 Along with Radio2 comes a new kind of RSS feed, one that really works for microblogs.
Along with Radio2 comes a new kind of RSS feed, one that really works for microblogs.
In the last few days, since Twitter announced their new developer roadmap, there's been a fair amount of writing done about using RSS as the basis for a distributed version of what Twitter does.
People who read this blog will already be familiar with this idea.
However one thing I haven't seen anyone write about is the question of titles. This is a big issue, the reason why it's hard to do what Twitter does in RSS, but thankfully not impossible.
Here's the thing. Twitter posts don't have titles.
No matter how you look at it, they don't have them. When you go to twitter.com all you get is a prompt that asks "What's happening?" In a sense this is the title of every Twitter post, without the question mark.
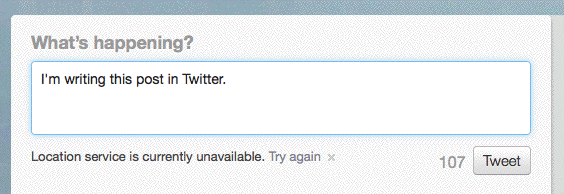{kind=link}
When you're constructing a minimal blogging tool, you have to allow for posts that don't have titles. And if you want Twitter users to be comfortable with it, that must be the default behavior.
Then if you look at the RSS feeds that Twitter generates, you'll notice that they reproduce the text of the tweet in both the title and the description. It looks awful in my aggregator, and I bet it looks awful in others. But if I were them, I might have done it this way. I assume this is because there are feed readers that won't deal with items that don't have titles. I think Google Reader works this way. So if you want to read a Twitter feed in Google Reader, and that must have been their number one feature request, and if the Google Reader guys aren't willing to budge, then go ahead and echo the tweet text in both places.
{kind=link}
I didn't go that way. I read the RSS 2.0 spec again, to be sure I had it right, and there's no requirement that an item have a title. "All elements of an item are optional, however at least one of title or description must be present." There's a reason for that, it's not an accident. Early blogs, like scripting.com, had posts without titles. If RSS was going to work for those blogs (and I had an incentive to make it work that way) it had to be permissible for items to not have titles. Any reader that can't handle them isn't really a RSS-reader, it's a subset-of-RSS-reader.
So my feeds won't be readable in those tools. Which is, to me, a feature not a bug. Because those guys seriously need to take another look at their product, in the age of Twitter, because they're not dealing with a very popular form of content. And they could be doing it, with a simple fix, and they should be looking at a retrofit in the near future, to become part of the distributed network that will develop alongside Twitter. As now seems virtually inevitable.
One more thing, if you've been reading the feeds that emanate from Radio2, you would have noticed that there's a new namespace coming along with it, called microblog. It's a place where I'm putting items that are needed to properly represent a microblog in RSS. If you're interested in this stuff you should have a look.
Minimal blogging tool, working!
In January I wrote about what I called the minimal blogging tool. The goal being to create a thin blogging tool that would compete with Twitter for simplicity. Of course that doesn't mean the design is easy. It took a lot of trying stuff this way then that but finally I'm happy with it. And it's in finishing-off state, the first real product shipment I've done since nine years. Feels pretty good.
The product is called Radio2 -- it's the continuation of the thread started by Radio UserLand in 2002.
So if it's nearing shipment, how does that work?
0. If you want to get an idea how it works without using any software, check out the docs.
1. If you really really really want to try it out now, send me an email to the address in the sidebar and I'll set the first ten people up with accounts on my server. This is just for you to try out. I'm not making any committments to hosting your site for any period of time. This is just for trying-out.
2. I am shipping it as a tool that runs in any Frontier-based environment. That includes the OPML Editor, and the runtime that's baked into EC2 for Poets. I've written a howto that explains how to install it. It requires some technical ability, but once you have it running, it's pretty reliable, I've found. We have a mail list going for support of sysops of EC2-for-Poets servers.
3. If you know someone who has a Radio2 server, you can ask them for an account on their server. Or a group of people can join together, pool resources, and run their own.
4. If you want to host the server elsewhere, not on EC2, I've prepared a download of just the OPML app taken off the EC2 server. It will stay in synch with the servers we're all running, but it doesn't have to be on EC2. Again, you should be something of a technical hero to run this, but not a super-geek, just someone who likes computers.
If you just want to keep track of development, look at the changes page. There's no feed for that page, by design. I want people to read it as a stream, not as separate bits. I don't see this changing anytime soon.
There's a lot more on the way. I'm going to keep programming. Hopefully the community has reached a level where it can support new servers coming online. If not, we'll keep iterating until it has reached that level.
Mike hit the jackpot
Mike Arrington wrote a milestone piece yesterday saying Google wouldn't make the mistake of overhyping whatever new thing it may or may not be cooking up to compete with Facebook.
Important thought.
I don't think I've ever seen this happen, in any cycle I've been witness to.
Mike's predecessors in previous loops, Ben Rosen, Esther Dyson, Stewart Alsop, John Markoff, Walt Mossberg, I'm sure I'll think of others, never said that hype wasn't a necessary part of making software successes. Their livelihoods depended on people coming to them with hype so they could turn it into ink on paper (or vapor on paper).
 When it came time to roll out stuff, the titans of their day, Bill Gates, the Visicalc guys, Mitch Kapor, Larry Ellison, Steve Jobs, John Doerr, Marc Andreesen, would always offer up a banquet for the press. And usually whatever they were hyping would flop. Hard. OS/2, Cairo, Hailstorm, Aritifical Intelligence, Object Oriented, TK!Solver, Agenda, The Semantic Web, even open source, when presented as a panacea for the tech industry was a major dud.
When it came time to roll out stuff, the titans of their day, Bill Gates, the Visicalc guys, Mitch Kapor, Larry Ellison, Steve Jobs, John Doerr, Marc Andreesen, would always offer up a banquet for the press. And usually whatever they were hyping would flop. Hard. OS/2, Cairo, Hailstorm, Aritifical Intelligence, Object Oriented, TK!Solver, Agenda, The Semantic Web, even open source, when presented as a panacea for the tech industry was a major dud.
Second acts generally express their wishes for success rather than actual success. The reporter's job is to muddle up the difference.
Meanwhile it's the stuff that doesn't get the hype that has a chance to go through the iterations needed to achieve market acceptance, off on the side, without millions of users showing up Day One. Almost every product we use was like that. (Recent Apple rollouts are the exceptions. Don't know how they do it. They must have quite a testing process going on behind the curtain.)
Mike basically said, in not so many words, if you want to know what's working, what the future will look like, don't look for the stuff that gets hyped to people like me. You have to look more broadly.
He's absolutely right about that. And it takes guts to be so clear.
Today's pot-luck pod-cast
Jay's on a jet plane today at the normal Rebooting the News time, so we're going to try something very different.
At noon, I'll play a song to get us in the mood, then we'll take calls on talkshoe.com. Use the widget below to find your way there.
Call in if you have something to say, a question to ask -- but please keep it nice -- R E S P E C T -- find out what it means to me!
And keep your comments as brief as possible. As you know I like to drone on and on, and you have to humor me cause it's my show. ![]()
BTW: If any of these talk radio guys want to pay me $500K, I could make you a browser-based UI that wouldn't leave users crying for their mommies.
PS: Here's the MP3.
My developer roadmap
Yesterday I wrote a post about Twitter's developer roadmap.
Full of potholes, detours, Do Not Enter signs. That's the road you're on if you're a corporate blogging silo. They made the choice to go in that direction a few years ago. This moment was inevitable the day they made it. And it doesn't make them bad people, or stupid, as some people say. It's a valid choice. Don't be so sure you wouldn't make it if you were in their place.
My roadmap...
In a comment under that piece, a developer from Feedly asks, basically, for my roadmap.
I posted a pointer to my linkblog feed.
http://static.reallysimple.org/users/dave/linkblog.xml
That's the center of my universe. It's still developing, I want to add some more stuff to the namespace, but it works.
So here's the roadmap:
1. Develop stuff that consumes feeds like that, and I'm happy. ![]()
2. Develop stuff that manages feeds like that, and I'm happy. ![]()
3. Develop tools that help users of #1 and #2 and I'm happy. ![]()
 See it's easy to make me happy. I'm already happy, having a lot of fun, building software around that format. If I were running a company that took on tens of millions in venture capital I'd have to tell you to go away. But I haven't, so I don't. I'm like Tom Sawyer with the whitewash fence. I'm having the time of my life. But yeah, if you insist, I'll share.
See it's easy to make me happy. I'm already happy, having a lot of fun, building software around that format. If I were running a company that took on tens of millions in venture capital I'd have to tell you to go away. But I haven't, so I don't. I'm like Tom Sawyer with the whitewash fence. I'm having the time of my life. But yeah, if you insist, I'll share.
BTW, to the people who say that, in order to use something other than Twitter, you have to leave Twitter -- that clearly is not true. So far the Twitter guys think it's okay for me to post to their network via my tool. However if they want to shut me down, please, do me a favor. I'm addicted to Twitter. Guys like me could use a little tough love. ![]()
PS: For a tour of the architecture, please read the stories linked to here.
Twitter's new developer roadmap
Ryan Sarver works at Twitter. He just posted a new developer roadmap, a few minutes ago. In it are all the things I was expecting:
1. If you make a Twitter client, you have a bit of time to get out of that business. If you were thinking about writing one, don't.
2. Twitter wants to control how tweets are presented everywhere. That means if you have an app that somehow displays them, you'd better read the new terms of service. You probably aren't allowed to do that anymore.
3. Analytics are OK, for now. Helping big companies manage their brands on Twitter, OK for now. Not clear what else.
 4. No mention of Twitpic, Yfrog. Instagram and Foursquare are "value-added content and vertical experiences."
4. No mention of Twitpic, Yfrog. Instagram and Foursquare are "value-added content and vertical experiences."
A personal note, I am so happy I cut the cord with Twitter long before they got to this point. I'm pretty far along in doing a new user interface for microblogging, one without many of Twitter's limits. Had I been trying these ideas out on their platform, today is the day I would have become officially illegal. But the writing was already on the wall, clearly.
The Internet remains the best place to develop because it is the Platform With No Platform Vendor. Every generation of developers learns this for themselves. When I wrote it Apple hadn't been reborn. I was thinking about the messes that Sun, Microsoft and Netscape were making. And finally getting myself out of the mess Apple made before Apple was making its new mess.
Facebook may have a huge installed base, but it's dead to me. I can't get there. The platform vendor is too active. Same with Twitter, same with Apple. Give me a void, something I can develop for, where I can follow the idea where ever it leads. Maybe there are only a few thousand users. Maybe only a few million. Hey, you can't be friends with everyone. ![]()
PS: You have to wonder why Twitter chose the weekend of SXSW to drop this bomb. Were they aware that large numbers of influential Twitter users were getting together in Austin to drink beer, eat BBQ and mumble disgruntlement about Twitter? Now they have something to bumble about!
PPS: Bad timing for Apple's rollout of the iPad 2. They were hoping to dominate the news with hordes of groping fanbois camped on the sidewalk outside Apple stores. Instead there's some real news (no not Twitter, Japan).
Looking for quake feeds
I'm sure there's a feed on each of the major news sites tying together all their quake coverage. I just wish I knew where they were.
When there's a huge story literally breaking over the planet (and maybe breaking the planet), we need the most accelerated access to news. Not to have to go hunting for it. We have the technology and standards to do it, totally mature, we just have to use it.
If your news organization has a feed that ties together your quake coverage, send me a pointer. I will of course publish the OPML subscription list and keep it current, as I did with the WikiLeaks OPML when it was the breaking mega-story.
Blocked from retweeting?
Earlier this evening I tried to retweet something, and got this message:
You have been blocked from retweeting this user's tweets at their request.
If you don't believe me, here's a screen shot.
{kind=link}
All kinds of thoughts come up.
1. I didn't know you could do that.
2. Is it in the user interface?
3. If not, how do you get this done?
 4. Why would someone want to do this?
4. Why would someone want to do this?
5. Retweeting seems pretty neutral. Not?
Anyway, I did a Google search and found it has come up before, so I'm not the only one. But not very often, which seems to indicate there is no user interface for it. Very odd.
BTW, "just blocking them" is not an answer, because a friend who I don't want to unfollow frequentlly RT's the person who has me blocked from RT'ing. If it gets annoying enough I guess I will have to unfollow the friend who I don't want to unfollow.
Also, it's that his tweets are private, they aren't. I am not following him. Another friend is retweeting them. Unless their "privacy" includes this feature, they aren't private.
In case it isn't obvious, Twitter is a morass of inconsistent rules about when it should and shouldn't show you stuff, and makes you block people when you have no interest in blocking them just to get another feature that comes along with blocking.
Apache plus Dropbox = Hello World
With all the money going into startups it's amazing that the underlying web isn't being built out.
 There have been some innovations in the basic web, the biggest in the last decade clearly is Dropbox, but even that is just a taste of nirvana. Their public folder is so incredibly useful. Amazing one of the hundreds of startups out there haven't seen fit to pick up that ball. Behind the scenes I've been urging Amazon and Rackspace to go there. Amazon's effort is so disappointing. They're such a great competent company. But they just don't understand the problem. I guess. Their product misses the mark, again and again.
There have been some innovations in the basic web, the biggest in the last decade clearly is Dropbox, but even that is just a taste of nirvana. Their public folder is so incredibly useful. Amazing one of the hundreds of startups out there haven't seen fit to pick up that ball. Behind the scenes I've been urging Amazon and Rackspace to go there. Amazon's effort is so disappointing. They're such a great competent company. But they just don't understand the problem. I guess. Their product misses the mark, again and again.
In a comment, Ryan Tate says: "It would be neat if someone combined S3's innovative pricing model with old-school Apache webhosting. Bonus points for supporting the S3 API."
I added of course that I want Dropbox too. And offered an explanation of why we're waiting so long. "The vendors aren't users." So many things waiting for this to be easy. It's as if the PC had been invented, but we were waiting for someone to create a word processor.
Update: An old friend from the dotcom days, Miko Matsumura, asks for a better explanation. Here goes..
I want to forget about running Apache. It should be a commodity. I want two ways to manage the content that's served for me by Apache. The S3 API, and Dropbox. I need a few of the features of htaccess files, the ability to specify my index file, error file, and to redirect permanently or temporarily. Maybe one or two other simple features. No dynamic bits. I pay for bandwidth and storage. Super-important that I pay. The hosting provider must be an entity whose longevity is obvious. Would be great to be able to pay in advance for 10, 25 or 100 years. As Ryan Tate says in a subsequent comment, with something like this in place, reliable, utility-level HTTP storage and serving, an industry could develop. One that, btw, would not be bubbly. Hope this explains it! ![]()
Can't run Scripting News on Amazon S3
 To review, Scripting News is mostly a static site with a few dynamic bits. All of them connected into the site via JavaScript includes. So theoretically the whole site could be moved into Amazon S3 using their new ability to specify an index file for a bucket (and it's sub-folders).
To review, Scripting News is mostly a static site with a few dynamic bits. All of them connected into the site via JavaScript includes. So theoretically the whole site could be moved into Amazon S3 using their new ability to specify an index file for a bucket (and it's sub-folders).
However, there are two problems, and I think the second one is a deal-stopper.
1. The inability to point scripting.com at the bucket. It must be a sub-domain because it must be a CNAME. I refuse to redirect scripting.com to www.scripting.com for religious reasons, although most others probably wouldn't mind. People I respect would. So I could use s3.scripting.com, which I kind of like. Anil Dash asked a question I hadn't thought of. You're putting someone else's brand on your site. Yeah. It's like "S3 brings you scripting.com." Seems they should have to pay for that. And further, it's an ad and I don't do ads here. But on the other side, it says very clearly to everyone who cares that this is an S3-hosted site, and so they know that if it works they should credit Amazon, and if it doesn't. Since this is a site with a large focus on people who develop for the web, it seems appropriate. So, all-in-all, this is an issue, there is no ideal solution, but there are workable ones.
2. Scattered through the folders are .htaccess files, that correct mistakes, glue the site to other sites, all around serve as a method of patching a site that's been around a long time, since 1994. There's a lot of that kind of patching in there. Of course S3 sees an .htaccess file as just another thing to serve up. So if I redirected scripting.com to s3.scripting.com, who knows what kind of hell would break loose. I don't remember all the things I patched this way over the years. I know the site works reasonably well. So I guess the bottom-line is that while I don't want to run Apache myself, this site needs to be served by Apache or something that emulates it. It seems that, unless I think of something else, S3 is for hosting new sites, not ones that have been around for a while.
Terrified of dying
Over on Reddit a guy with terminal cancer posted that he was going to die in 51 hours and wanted to spend some of this time talking about it with Reddit users. Lots of interesting stuff in the thread. (BTW, it was a hoax. No matter, the ideas are valuable anyway.)
Someone asked if he was scared of dying. He said he was terrified. What a word. From there the discussion goes to the usual places, the things we have all thought of. But there's a new idea I have, at least for me, that I've never written about. So I thought I should.
Every animal has the instinct to fight death. I suppose there are occasional mutations, individuals that don't care whether they live or die, but they would get culled quickly. The more fanatic you are about not dying the more likely you are to reproduce. Evolution reinforces this trait.
I think that's where the terror comes from. If we lived in a totally benign environment, where our time of death was fixed, and nothing could change it, not even our disposition, we would never have developed the terror.
This suggests there may be a way to medicate the terror in the last days of life, so we shrug it off the way we wish we could and don't. And focus on closure the people and things we care about.
I could run Scripting News from S3
 scripting.com is served by Apache running on Windows on EC2. It usually works pretty well, but sometimes, usually when there's more traffic, the server stops responding and won't reboot. Eventually, after enough reboots it comes back up, but every time it happens I think about how to get out of this situation.
scripting.com is served by Apache running on Windows on EC2. It usually works pretty well, but sometimes, usually when there's more traffic, the server stops responding and won't reboot. Eventually, after enough reboots it comes back up, but every time it happens I think about how to get out of this situation.
I don't want to run Apache to serve static web content. I want to have that completely taken care of for me. S3 was frustratingly close to being exactly what I want. It just got closer but still isn't exactly what I want. I could run Scripting News from an S3 bucket, but it wouldn't be accessible at scripting.com because that must be an A record, and blah blah blah. It's such a well-rehearsed story now.
I subscribe to the no-www philosophy. The shorter the URL the better. I always redirect www.scripting.com to scripting.com. I've come to think of "www" as creepy.
So that's the downside of hosting Scripting News at S3. And I am so annoyed by www as a prefix I would use something like s3.
Try it -- it works. It's kept current. All I have to do is redirect scripting.com to s3.scripting.com and goodbye Apache.
I wish Amazon would figure out how to let us use the domain name itself for one of these spiffy static sites.
But I may go ahead and make the switch anyway. I think s3.scripting.com is kind of cool. ![]()
The limits of Twitter and Facebook, the bubble
Two key facts about Twitter and Facebook.
1. Twitter's mistake was building a product they didn't really use. I've never seen it work out well when the top guys at a company aren't passionate users of their own product. They can be quirky, that just comes out in the product. Gates and Windows. Jobs and the Mac. Marc Andreessen and Netscape. Etc etc. When the people who run Twitter get on stage and talk about their product, it's very different from the thing we're using. You can feel the discomfort. It's distant. It also comes through in the decisions they've made re business models.
2. Facebook can only rise so far because they're hiring from the same talent pool as all the other Silicon Valley companies. They all think they're going to be different, and for a while they are. Until they grow so big that everything that was different about them gets diluted. Eventually the singular Silicon Valley Company takes over. I remember when Apple was young, their execs were the most wonderful people in the world. Almost as if "wonderful" was a technical term. They were thinking about taking over and running third world countries after their Apple options vested. Seriously (and I'm not making fun of them). But they all fall to earth, and become the foundations and plaster for the next upstart.
Are we in a bubble? Yes, this is a bubble. All the frenzied startup activity and still the VCs raise more money to invest. Not enough inventory. We need more young people to play the role of entrepreneur. It's so analogous to the real estate bubble where the only bad bet was to own the actual real estate because that was so real. The money was being made off the lies. In this bubble the people who are going to get hurt are the legions of young people. Most of them aren't entrepreneurs. As a percentage of the population, the people who really have the drive and fortitude to stick it out is infinitesmal. But that isn't the myth -- it's also like the housing boom where everyone could be a home owner. In 2011 every young person can be an entrepreneur, esp if he or she knows how to code. That's the bubble, right there.
How to use the new host-a-website feature on S3
You can find all the links on Werner Vogel's blog. I share his enthusiasm for the new host-a-website feature. I was asking for it for a long time. I guess, from reading the tea leaves, he was too. ![]()
Anyway, I had to do a bunch of trial and error to get my first S3-hosted static site configured. I wanted to leave a howto behind me so next time I won't have to do the head-scratching again. Maybe it will help you too.
 Suppose the domain you want to host on S3 is r2.reallysimple.org. And the index file for that domain will be index.html. This is what you do.
Suppose the domain you want to host on S3 is r2.reallysimple.org. And the index file for that domain will be index.html. This is what you do.
1. Go to the S3 panel on the AWS website and create a new bucket called r2.reallysimple.org in the US-Standard region.
2. Upload a file called index.html to the new bucket. Say something simple like Hello World. You can copy the HTML from my test file if you want.
3. Click on Properties at the top of the right panel, then click on Website in the lower-right panel. Click the Enabled checkbox, and enter index.html as the Index Document. Click Save.
{kind=link}
{kind=link}
4. Click Permissions in the lower-right panel. Then click on Edit bucket policy. Paste in the template text you grab from this file. Edit it to replace YOUR-BUCKET-NAME-GOES-HERE with the name of your bucket (in the example r2.reallysimple.org). Click Save.
{kind=link}
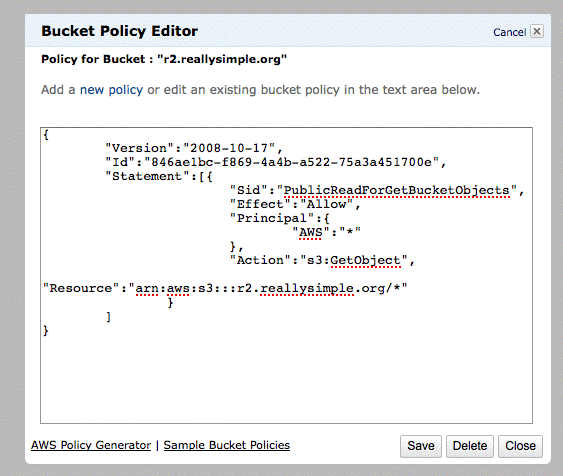{kind=link}
5. Now go to your domain registrar, and map r2.reallysimple.org as a CNAME to r2.reallysimple.org.s3-website-us-east-1.amazonaws.com.
Now you should be able to go r2.reallysimple.org and see the text of your index file. ![]()
Why I love Adjix
 I just read a review of five URL shorteners and added a comment recommending the one I'm building my systems on, Adjix.
I just read a review of five URL shorteners and added a comment recommending the one I'm building my systems on, Adjix.
Adjix is imho, the best because it automatically stores each link it shortens in an Amazon S3 bucket that I own. If they ever go away, or if for some reason I decide to move on, my links won't break (at least not because of them). I also use a custom domain for my URLs. So I get complete data portability at no cost. Absolutely no lockin.
I don't own any stock in Adjix, or have any reason to recommend it other than it is a great service.
I know a lot of people haven't heard of it, but it's really important. Someday a lot of these links are going to break. I'm doing everything I can to be sure that mine last. I know other people care about this. Adjix has made it work.
What makes local sites hum?
 Lately it's dawning on people that the mass aggregators of local information aren't achieving critical mass among the locals. Outside.in, a site that never made much sense to me, sold to AOL for $10 million. A lot less money than the VCs had invested in it.
Lately it's dawning on people that the mass aggregators of local information aren't achieving critical mass among the locals. Outside.in, a site that never made much sense to me, sold to AOL for $10 million. A lot less money than the VCs had invested in it.
Anyway, I thought now would be a good time to remind that in spots around the world and even in the US, local sites are kicking butt. Here in NYC, we have quite a few. I keep an aggregator of East Village blogs. Pretty interesting reading.
A couple of my favorites, close to home and a former home are NYU Local and Berkeleyside.
I think the common thing is people who care. Who wants to read local news prepared by software. I find it interesting to know what interests people near me. I find the idea of an algorithm making the choices to be sterile, void of nutrients. Unhappy!
Hey even the curmudgeonly Berkeley Daily Planet has a pretty decent website these days (few offsite links, but hey that's who they are).
What is a dickbar?
Being from the East Coast, as I am, I recognize the term "dickbar" as an eastcoastism. It refers to a new feature in Twitter for the iPhone which brings the first instream advertising to the eyeballs of Twitter users. It's the kind of thing a guy from Philly, Gruber, who roots for the Yankees might say. As far as I know he coined the term.
 This is what a dickbar looks like.
This is what a dickbar looks like.
Gruber is referring to the first rumblings of the promised business model from Chicagoan Dick Costolo, the (relatively) new CEO of Twitter. He, I conclude is 1/2 of the "dick" in dickbar.
The other half is how you feel for believing that Twitter would do something classy and interesting with advertising, as we were promised when, the newly minted COO of Twitter, the same Dick Costolo told us we would love their advertising. Yeah uhuh. Us East Coast guys have a bridge we'd like to sell you. It connects Manhattan with the great borough of Brooklyn. Real cheap. ![]()
Advertising works for Google because when you go to Google you're looking for something. That's why you went there. So they can show you something like what you asked for and hope in some way it comes closer to what you want. Or, like most advertising, it could be a distraction. We noticed that people who drive BMWs also like Starbucks. We don't know why, but we thought we'd launch our new coffee place by running an ad next to searches for BMWs. It might just work. Or not.
No one yet knows why people use Twitter. I'm a regular. I use it for the same reason I used to smoke two packs of Marlboro Lights every day. It's a hard habit to break. No one has any idea if it's a good place to drop ads. We're going to find out, it seems.
But the rabbis and linguists of Twitter are having a lot of fun with the dickbar concept.
And a bit of sympathy for the people at Twitter, who are cursed to have a service that makes it easy for people to complain about the service itself. I've been there. Supporting bloggers with a commercial product or service is generally not a lot of fun. ![]()
PS: When I discovered that dickbar.org wasn't taken, I had to get it.
Using DNS as a thin ID system
 Just thinking out loud here.
Just thinking out loud here.
Suppose a user had control of a name that can be looked up through DNS.
Something like: dave.me or dave.easy.com, for example.
The former would be done through a registrar, the latter by a web service.
Suppose in both cases the user could define a file whose name would only be known to him. That's the password. When you sign in you'd enter the domain and the name of the file where username and password are requested.
Then the site requesting a validated ID would make this request:
http://username/password
If what came back is a 404, you're not authorized.
If a 200 came back -- you're in.
The body of the request could be something like a feed or an OPML file with info about the person. Basic stuff that any authenticated site is allowed to have.
Seems that's about as thin as an ID system can get.
And there's nothing innovative about it. We just need something like this that's quick easy for users to set up, with a name they're likely to trust.
Having a big prob with EC2
I have an AMI that I created from Windows server AMI, that's used in the EC2 for Poets tutorial. It worked really well at first. I had to launch a new instance a week or so ago, and waited for over an hour and it was still telling me it couldn't get a Windows password for it.
In desperation I left it running overnight, came back to it 24 hours later, and this time it gave me the password.
Today I got a report from a user that he's seeing the same thing (though he hasn't waited to the 24 hours yet).
I just launched an instance myself, at 3:15PM, and now at 4:40PM it's still saying no password.
I will, once I get one of these guys to launch, create a fresh AMI and hope that clears the problem. Whatever happened this is really bad. I assumed that the stuff inside the AMI didn't need to be backed up. Bad assumption! ![]()
Any help or advice would be much appreciated.
Update: At 9PM still no Windows password. Posted question on Amazon support.
Update: 7:45AM Friday, still no Windows password.
Update: 9:30AM, still no luck. Launched a second instance. Maybe this one will do better?
Update: 3:40PM, got the password! ![]()
Thin identity -- the missing web service
 I wish there were a web service that had a simple XML and/or JSON interface that made it easy for a user to establish a username and password.
I wish there were a web service that had a simple XML and/or JSON interface that made it easy for a user to establish a username and password.
Such a service, if it had reasonable terms of service, could clean up among developers who want to invest in a net outside of Twitter, Facebook and Apple.
Why doesn't Amazon have a simple authentication service? This person says he or she is bullmancuso. Great, is this his password? Yes or no. That's all we need.
How about Visa or Mastercard. A bank?
I suspect we don't have it because of the confusion about OAuth. Shame cause it's desperately needed.
Who will play Assange in Spielberg's movie?
Fascinating news that Steven Spielberg has acquired the movie rights to the Guardian Wikileaks book.
Spielberg is such a serious director, it's possible his movie might actually capture the substance of Wikileaks, and not be superficial, as, for example -- the Aaron Sorkin version of the Facebook story.
This raises the question of who will play Julian Assange?
I immediately thought of the guy who plays him on Saturday Night Live.
I bet Jim Carrey will want the part.
Who do you think Spielberg will go with?
Will today's Apple event be webcast?
We all know Apple is announcing the new iPad today.
The last couple of Apple events have been webcast in beautiful hi-def video.
Wondering if today's event will be, as well?
I also asked the question in my linkblog feed, and as a result, on Twitter.
Also on Hacker News.
Update: According to @jarin, it is not being webcast.