 I've long-ago gotten over the shock of how you have to stack callbacks in JavaScript. I kind of like the puzzles now, but I sure didn't at the beginning, because I strive to make my code read like the pseudocode that would be used to describe it. And there's no way to do that with JS. So Node is off the hook, it's not its fault JS is that way.
I've long-ago gotten over the shock of how you have to stack callbacks in JavaScript. I kind of like the puzzles now, but I sure didn't at the beginning, because I strive to make my code read like the pseudocode that would be used to describe it. And there's no way to do that with JS. So Node is off the hook, it's not its fault JS is that way.
I really like the way package.json works. I like the docs that are available for all the elements. As a metadata guy (I played a role in defining RSS and XML-RPC), I appreciate a good set of names that covers all the bases.
And Node is a network of code. I've never seen this so well-developed. We did stuff like this in the Frontier community, but this is better, and of course it should be -- it's 2014 not 1994.
I just put together a routine that makes an HTTP request taking a URL as a parameter. It came together nicely. I used a URL parser written by Steven Levithan and the example in the nodejs.org docs.
- Update: Probably should be using the url package.
I still have to decide how I'm going to parse my XML, or if I will. What I need to do can be accomplished with string search, and maybe bringing in a whole XML engine is too much. I just need to get a value from the <head> section of an OPML document. Not a big deal. And I see Dan MacTough has already written a routine for parsing an OPML document. So I have footsteps to follow.
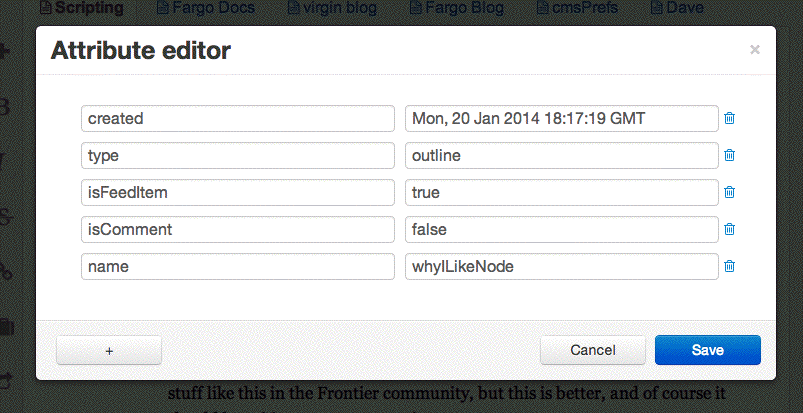
Nodejitsu is actually something I think we could write a Poets tutorial for that would be a lot simpler than setting up an EC2 instance, as we did with the earlier poets doc. You just have to tell GitHub your Nodejitsu username and password. Then the connection is made. Adding environment variables is no more difficult than editing the attributes of a headline in Fargo.
{kind=link}
Where I'm trying to get to with this is a simple server app that acts as a storage backend for the next release of Fargo. I want something I can give to anyone who wants to run their own server. Mine will be in JS and run in Node. I'll probably provide a howto for Nodejitsu. I'm using the MIT license for this code. Nothing fancy here (by design). Just a way for a user's outliner to say "here's some static HTML, please make it accessible over the web."
Node will do this nicely.